继续斗智斗勇中。已经开始谷歌大法好了。。
python challenge 21
invader.zip
Yes! This is really level 21 in here.
And yes, After you solve it, you'll be in level 22!
Now for the level:
* We used to play this game when we were kids
* When I had no idea what to do, I looked backwards.
说这是个小时候的游戏,击鼓传花,国外的玩法不一样,需要一层层地拆传递的那个东西
level 20下载到的那个压缩包的package.pack文件是个压缩文件,使用了zlib和bz2两种方式压缩。
需要根据上一次解压得到的结果,判断下一次解压用zlib还是bz2,以及判断得到的数据是正向的还是要look backwards。
Zlib压缩的数据开头第一个字节是"\x78",ASCII码是"x".
BZ压缩的数据开头两个字节是"\x42\x7A",ASCII码是"BZ".
def package():
import bz2
import zlib
data = open("files/invader/package.pack", "rb+").read()
result = []
while True:
if data.startswith("x\x9c"):
data = zlib.decompress(data)
result.append(" ")
elif data.startswith("BZ"):
data = bz2.decompress(data)
result.append("#")
elif data.endswith("\x9cx"):
data = data[::-1]
result.append("\n")
elif data.endswith("ZB"):
data = data[::-1]
result.append("*")
else:
break
print "".join(result)
>>>
### ### ######## ######## ########## ########
####### ####### ######### ######### ######### #########
## ## ## ## ## ## ## ## ## ## ##
## ## ## ## ## ## ## ## ## ##
## ## ## ######### ######### ######## #########
## ## ## ######## ######## ######## ########
## ## ## ## ## ## ## ##
## ## ## ## ## ## ## ## ##
####### ####### ## ## ######### ## ##
### ### ## ## ########## ## ##
其中四种情况的记录标志符“#\n”等这些可以自己设置,最后将其反转标志替换成回车\n,zlib标志替换成空字符,BZ标志替换成#即可打印出答案。
python challenge 22
http://www.pythonchallenge.com/pc/hex/copper.html

查看页面源代码提示:or maybe white.gif would be more bright
将copper.html替换为white.gif显示一张黑色图片,黑的什么都看不到。
google大法说了每帧图上有一个不同的RGB点。
用ps打开,由于是gif动态图只能打开其中一帧,看看RGB全是(0,0,0),鼠标晃晃就找到了那个不同的RGB(8,8,8)。
然后我么把这张gif拆帧并将RGB(8,8,8)改为白色RGB(255,255,255),这样就能清晰的看到运动轨迹了。

如果上图白点不动的话刷新下页面,或者右键图片审查元素,拿到gif图片链接浏览器直接访问。
代码整理在github
看到运动轨迹后思路就很清楚了,该动画总共133帧,白点围绕100,100左右微小变动,
联想这一关的图片(一个游戏操纵杆),把这些变动的点连接起来。
最后的结果显示通过操纵点的运动一共画出了5个字母的轮廓,所以当白点回归到中心的时候,就是画下一个字母的信号了。
def copper():
from PIL import Image, ImageDraw, ImageSequence
org_img = Image.open("img/white.gif")
new_img = Image.new('RGB', org_img.size, "black")
new_img_draw = ImageDraw.Draw(new_img)
x = 0
y = 0
for s in ImageSequence.Iterator(org_img):
left, upper, right, lower = org_img.getbbox()
dx = left-100
dy = upper-100
x += dx
y += dy
if dx == dy == 0:
x += 20
y += 30
new_img_draw.point((x, y))
new_img.save("img/copper.png")最后生成图片中字母即为level23入口: bonus.html
python challenge 23
http://www.pythonchallenge.com/pc/hex/bonus.html

看网页源码提示:
it can't find it. this is an undocumented module
va gur snpr bs jung?va gur snpr bs jung?这段字符串想到了第二关的移位,由于不知道移几位,因此做个枚举
def bonus():
def shift(str_value, shift_num):
ret_list = []
alphas = list(str_value)
for alpha in alphas:
temp_ord = ord(alpha) + shift_num
if 97 <= temp_ord <= 122:
ret_list.append(chr(temp_ord))
elif temp_ord > 122:
ret_list.append(chr(temp_ord - 122 + 96))
else:
ret_list.append(" ")
return "".join(ret_list)
org_str = "va gur snpr bs jung"
for i in range(1, 26):
print ">>%d -> %s" % (i, shift(org_str, i))看输出信息:
>>1 -> wb hvs toqs ct kvoh
>>2 -> xc iwt uprt du lwpi
>>3 -> yd jxu vqsu ev mxqj
>>4 -> ze kyv wrtv fw nyrk
>>5 -> af lzw xsuw gx ozsl
>>6 -> bg max ytvx hy patm
>>7 -> ch nby zuwy iz qbun
>>8 -> di ocz avxz ja rcvo
>>9 -> ej pda bwya kb sdwp
>>10 -> fk qeb cxzb lc texq
>>11 -> gl rfc dyac md ufyr
>>12 -> hm sgd ezbd ne vgzs
>>13 -> in the face of what
>>14 -> jo uif gbdf pg xibu
>>15 -> kp vjg hceg qh yjcv
>>16 -> lq wkh idfh ri zkdw
>>17 -> mr xli jegi sj alex
...循环右移13位的时候出现了正常的字符串in the face of what?这意思是this..
再看第一个提示this is an undocumented module,在python导入this模块试试
The Zen of Python, by Tim Peters
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!In the face of ambiguity, refuse the temptation to guess.
答案:ambiguity
python challenge 24
http://www.pythonchallenge.com/pc/hex/ambiguity.html

这一关的图片是一张迷宫地图(641, 641),只不过白色部分是迷宫的墙,深色部分是路。
用ps查看像素点,可以看出墙部分的RGB=(255,255,255),路的RGB=(x,0,0)。
根据标题from top to bottom的提示,入口就是图片的右上角,出口就是图片的左下角。
用ps看下右上角的入口点:
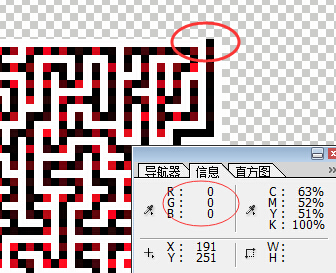
因此最开始通过getpixel(x, 0)[0]=0 找到入口点位置。
同理左下角出口点通过getpixel(x, 640)[0]=0 找到。
代码逻辑:
1.从入口点开始向四个方向找下个坐标点,找到后作为下一个入口点,并将当前像素点标白(255,255,255)
2.如果找到两个以上的下个出口坐标,即到了分岔口,备份之前的坐标队列,以此分岔口作为新的入口点,
3.如果未找到出口,则退回到上个分岔口继续查找。
最后生成的图片可以看到完成的迷宫路径:

显然这还不是谜底,在仔细观察迷宫的路径,可以发现每个一个像素点,路径上的颜色就会变化,
将这些像素点的R通道数据用二进制写到文件,打开可以发现前两位是PK ,那么这些信息其实是构成了一个ZIP文件。
更改后缀,解压,里面有两个文件,maze.jpg和mybroken.zip,其中maze.jpg图片上的lake就是谜底了。
完整代码:
def ambiguity():
import Image
org_img = Image.open("img/maze.png").getdata()
org_img_size = org_img.size
new_img = Image.new("RGBA", org_img_size, "black")
start_pos, end_pos = None, None
start_pos_count, end_pos_count = 0, 0
for x in range(org_img_size[0]):
if org_img.getpixel((x, 0))[0] == 0:
start_pos = (x, 0)
start_pos_count += 1
if org_img.getpixel((x, org_img_size[1]-1))[0] == 0:
end_pos = (x, org_img_size[1]-1)
end_pos_count += 1
if start_pos is None or end_pos is None or start_pos_count != 1 or end_pos_count != 1:
print "[error] : get start pos or end pos error!"
return False
print "[*] start_pos: %s and end_pos: %s" % (start_pos, end_pos)
path = []
whole_path = []
# 右 下 左 上
dire = [(1, 0), (0, 1), (-1, 0), (0, -1)]
wall = (255,)*4
while start_pos != end_pos:
org_img.putpixel(start_pos, wall)
flag = 0
new_pos = start_pos
for offset in dire:
try:
pp = (start_pos[0]+offset[0], start_pos[1]+offset[1])
if org_img.getpixel(pp) != wall:
flag += 1
new_pos = pp
except Exception, e:
print str(e)
pass
# 未找到下个出口
if flag == 0:
if not path:
path = whole_path.pop()
continue
start_pos = path[0]
path = []
# 分岔口,找到多个像素点,备份之前的坐标队列,以此分岔口作为新的入口点
elif flag > 1:
whole_path.append(path)
path = [start_pos]
start_pos = new_pos
# 找到唯一出口,flag = 1
else:
path.append(start_pos)
start_pos = new_pos
path.append(start_pos)
whole_path.append(path)
org_img = Image.open("img/maze.png").getdata()
data = []
for path in whole_path:
for k in path:
new_img.putpixel(k, wall)
data.append(org_img.getpixel(k)[0])
out = open("files/out24.zip", "wb")
for i in data[1::2]:
out.write(chr(i))
out.close()
new_img.save("img/out24.png")该题解迷宫逻辑参考PythonChallenge 挑战之路 Level-24
python challenge 25
http://www.pythonchallenge.com/pc/hex/lake.html

谷歌大法好:
这是一幅拼图模样的图片,根据网页源码里的提示can you see the waves?,这一关还要用到wave模块。
把URL后缀改为lake1.wav,lake2.wav,…,lake25会得到25个wav文件。
每个wav文件为10800字节,将三个作为一个像素,可得到一张10800/3=60x60大小的图片。
这25个wav文件对应着刚才的25块拼图,把这25个wav文件的内容依次拼起来,会得到一张300x300大小的图片。
def lake():
from PIL import Image
import requests
import base64
import StringIO
import wave
headers = {
"Authorization": "Basic %s" % base64.encodestring("butter:fly").replace("\n", "")
}
wave_url = 'http://www.pythonchallenge.com/pc/hex/lake%i.wav'
new_img = Image.new('RGB', (300, 300))
for i in range(25):
print "%i/%i" % (i + 1, 25)
wave_content = requests.get(wave_url % (i + 1), headers=headers).content
data = wave.open(StringIO.StringIO(wave_content))
patch = Image.fromstring('RGB', (60, 60), data.readframes(data.getnframes()))
pos = (60 * (i % 5), 60 * (i / 5))
new_img.paste(patch, pos)
new_img.save("img/out25.jpg")
最终得到的图片中单词为最后答案:decent

python challenge 26
http://www.pythonchallenge.com/pc/hex/decent.html

看网页源码中的提示:
1.be a man - apologize!
2.you've got his e-mail
3.Hurry up, I'm missing the boat提示让你先发邮件去道歉,邮箱哪里来,看19关的源码中有段没有用到的记录:
From: leopold.moz@pythonchallenge.com
Subject: what do you mean by "open the attachment?"
Mime-version: 1.0
Content-type: Multipart/mixed; boundary="===============1295515792=="
It is so much easier for you, youngsters.
Maybe my computer is out of order.
I have a real work to do and I must know what's inside!
...找到邮箱leopold.moz@pythonchallenge.com,要道歉,发送内容是什么?
看23关源码中没有用到的记录:
TODO: do you owe someone an apology? now it is a good time to
tell him that you are sorry. Please show good manners although
it has nothing to do with this level.现在就可以去给leopold.moz@pythonchallenge.com发送内容为sorry的邮件。
python发邮件模块网上很多,就几行代码,这里我直接用我邮箱发,然后收到回复:
从回复的邮件里得到了一个MD5值:bbb8b499a0eef99b52c7f13f4e78c24b以及它提到的broken.zip文件。这个解压文件在24关中得到,在解压的时候会提示CRC效验失败,也就是说缺少部分数据。但实际上用7z解压时候是可以解压出文件的。
但正常的过程应该是这个MD5值应该就是那个broken.zip的MD5值,需要将原文件的每个字节枚举看得到的MD5值是否为该MD5值,从而得到正确的文件。
def decent():
import hashlib
f_content = open("files/mybroken.zip", "rb").read()
for i in range(len(f_content)):
for j in range(256):
new_content = "".join([f_content[:i], chr(j), f_content[i+1:]])
if hashlib.md5(new_content).hexdigest() == "bbb8b499a0eef99b52c7f13f4e78c24b":
open("files/mybroken_new.zip", "wb").write(new_content)
print "offset %d -> %d" % (i, j)
>>> offset 1234 -> 168最后解压正确的zip文件得到一张图片

将得到的单词speed和提示Hurry up,I'm missing the boat组合起来得到下关答案speedboat
python challenge 27
http://www.pythonchallenge.com/pc/hex/speedboat.html

谷歌大法好,要利用调色板这些东西,调色板可参考调色板palette详解
首先查看源码,将zigzag.gif下载下来

这时候每个像素的上的信息是调色板的索引号,然后就需要用实际的颜色替换索引号得到等价的图片信息。然后将这些数据与原图片信息对比,将不同的坐标点标记颜色,如新建一个黑底图片标白,最后得到一张图片。

图片左边是not,右边是word,下边是busy?,中间是钥匙,合起来是not key word。
然后将两个图片不相同的字节放在一起,最后经过颜色替换索引号得到的图片不同的数据得到一个bz压缩文件,解压出来并找到那些关键字里面哪些不是key word打印出,最后得到答案。
def speedboat():
import Image
import string
import bz2
import keyword
img = Image.open("img/zigzag.gif")
img_content = img.tostring()
img_plt = img.palette.getdata()[1][::3]
trans = string.maketrans("".join([chr(i) for i in range(256)]), img_plt)
img_tran = img_content.translate(trans)
# compare
diff = ["", ""]
img = Image.new("1", img.size, 0)
for i in range(1, len(img_content)):
if img_content[i] != img_tran[i-1]:
diff[0] += img_content[i]
diff[1] += img_tran[i-1]
img.putpixel(((i-1) % img.size[0], (i-1)/img.size[0]), 1)
img.save("img/out27.png")
text = bz2.decompress(diff[0])
# extract key
for i in text.split():
if not keyword.iskeyword(i):
print i
>>> ../ring/bell.html
repeat
switch
repeat
../ring/bell.html
../ring/bell.html
../ring/bell.html
...得到28关链接为http://www.pythonchallenge.com/pc/ring/bell.htm
账户名:repeat, 密码:switch


没有评论:
发表评论