背景
UAC(User Account Control,用户帐户控制)是微软为提高系统安全而在Windows Vista中引入的新技术,它要求用户在执行可能会影响计算机运行的操作或执行更改影响其他用户的设置的操作之前,提供权限或管理员密码。也就是说一旦用户允许启动的应用程序通过UAC验证,那么这个程序也就有了管理员权限。如果我们通过某种方式劫持了通过用户UAC验证的程序,那么相应的我们的程序也就实现了提权的过程。
UAC(User Account Control,用户帐户控制)是微软为提高系统安全而在Windows Vista中引入的新技术,它要求用户在执行可能会影响计算机运行的操作或执行更改影响其他用户的设置的操作之前,提供权限或管理员密码。也就是说一旦用户允许启动的应用程序通过UAC验证,那么这个程序也就有了管理员权限。如果我们通过某种方式劫持了通过用户UAC验证的程序,那么相应的我们的程序也就实现了提权的过程。
继续斗智斗勇中。已经开始谷歌大法好了。。
invader.zip
Yes! This is really level 21 in here.
And yes, After you solve it, you'll be in level 22!
Now for the level:
* We used to play this game when we were kids
* When I had no idea what to do, I looked backwards.
说这是个小时候的游戏,击鼓传花,国外的玩法不一样,需要一层层地拆传递的那个东西
level 20下载到的那个压缩包的package.pack文件是个压缩文件,使用了zlib和bz2两种方式压缩。
需要根据上一次解压得到的结果,判断下一次解压用zlib还是bz2,以及判断得到的数据是正向的还是要look backwards。
Zlib压缩的数据开头第一个字节是"\x78",ASCII码是"x".
BZ压缩的数据开头两个字节是"\x42\x7A",ASCII码是"BZ".
def package():
import bz2
import zlib
data = open("files/invader/package.pack", "rb+").read()
result = []
while True:
if data.startswith("x\x9c"):
data = zlib.decompress(data)
result.append(" ")
elif data.startswith("BZ"):
data = bz2.decompress(data)
result.append("#")
elif data.endswith("\x9cx"):
data = data[::-1]
result.append("\n")
elif data.endswith("ZB"):
data = data[::-1]
result.append("*")
else:
break
print "".join(result)
>>>
### ### ######## ######## ########## ########
####### ####### ######### ######### ######### #########
## ## ## ## ## ## ## ## ## ## ##
## ## ## ## ## ## ## ## ## ##
## ## ## ######### ######### ######## #########
## ## ## ######## ######## ######## ########
## ## ## ## ## ## ## ##
## ## ## ## ## ## ## ## ##
####### ####### ## ## ######### ## ##
### ### ## ## ########## ## ##
其中四种情况的记录标志符“#\n”等这些可以自己设置,最后将其反转标志替换成回车\n,zlib标志替换成空字符,BZ标志替换成#即可打印出答案。
http://www.pythonchallenge.com/pc/hex/copper.html

查看页面源代码提示:or maybe white.gif would be more bright
将copper.html替换为white.gif显示一张黑色图片,黑的什么都看不到。
google大法说了每帧图上有一个不同的RGB点。
用ps打开,由于是gif动态图只能打开其中一帧,看看RGB全是(0,0,0),鼠标晃晃就找到了那个不同的RGB(8,8,8)。
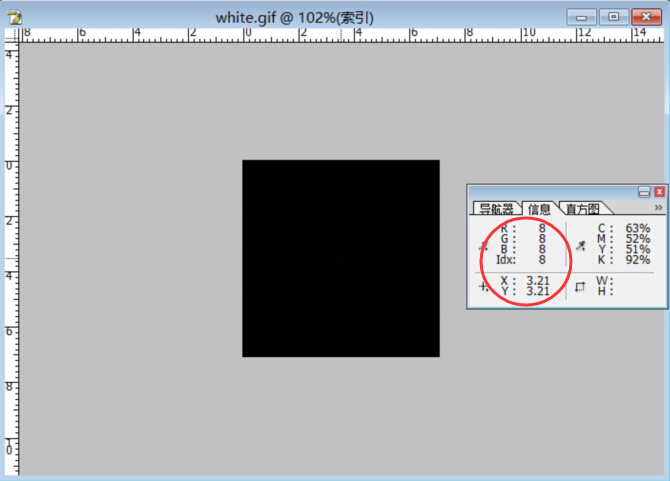
然后我么把这张gif拆帧并将RGB(8,8,8)改为白色RGB(255,255,255),这样就能清晰的看到运动轨迹了。

如果上图白点不动的话刷新下页面,或者右键图片审查元素,拿到gif图片链接浏览器直接访问。
代码整理在github
看到运动轨迹后思路就很清楚了,该动画总共133帧,白点围绕100,100左右微小变动,
联想这一关的图片(一个游戏操纵杆),把这些变动的点连接起来。
最后的结果显示通过操纵点的运动一共画出了5个字母的轮廓,所以当白点回归到中心的时候,就是画下一个字母的信号了。
def copper():
from PIL import Image, ImageDraw, ImageSequence
org_img = Image.open("img/white.gif")
new_img = Image.new('RGB', org_img.size, "black")
new_img_draw = ImageDraw.Draw(new_img)
x = 0
y = 0
for s in ImageSequence.Iterator(org_img):
left, upper, right, lower = org_img.getbbox()
dx = left-100
dy = upper-100
x += dx
y += dy
if dx == dy == 0:
x += 20
y += 30
new_img_draw.point((x, y))
new_img.save("img/copper.png")最后生成图片中字母即为level23入口: bonus.html
http://www.pythonchallenge.com/pc/hex/bonus.html

看网页源码提示:
it can't find it. this is an undocumented module
va gur snpr bs jung?va gur snpr bs jung?这段字符串想到了第二关的移位,由于不知道移几位,因此做个枚举
def bonus():
def shift(str_value, shift_num):
ret_list = []
alphas = list(str_value)
for alpha in alphas:
temp_ord = ord(alpha) + shift_num
if 97 <= temp_ord <= 122:
ret_list.append(chr(temp_ord))
elif temp_ord > 122:
ret_list.append(chr(temp_ord - 122 + 96))
else:
ret_list.append(" ")
return "".join(ret_list)
org_str = "va gur snpr bs jung"
for i in range(1, 26):
print ">>%d -> %s" % (i, shift(org_str, i))看输出信息:
>>1 -> wb hvs toqs ct kvoh
>>2 -> xc iwt uprt du lwpi
>>3 -> yd jxu vqsu ev mxqj
>>4 -> ze kyv wrtv fw nyrk
>>5 -> af lzw xsuw gx ozsl
>>6 -> bg max ytvx hy patm
>>7 -> ch nby zuwy iz qbun
>>8 -> di ocz avxz ja rcvo
>>9 -> ej pda bwya kb sdwp
>>10 -> fk qeb cxzb lc texq
>>11 -> gl rfc dyac md ufyr
>>12 -> hm sgd ezbd ne vgzs
>>13 -> in the face of what
>>14 -> jo uif gbdf pg xibu
>>15 -> kp vjg hceg qh yjcv
>>16 -> lq wkh idfh ri zkdw
>>17 -> mr xli jegi sj alex
...循环右移13位的时候出现了正常的字符串in the face of what?这意思是this..
再看第一个提示this is an undocumented module,在python导入this模块试试
The Zen of Python, by Tim Peters
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!In the face of ambiguity, refuse the temptation to guess.
答案:ambiguity
http://www.pythonchallenge.com/pc/hex/ambiguity.html

这一关的图片是一张迷宫地图(641, 641),只不过白色部分是迷宫的墙,深色部分是路。
用ps查看像素点,可以看出墙部分的RGB=(255,255,255),路的RGB=(x,0,0)。
根据标题from top to bottom的提示,入口就是图片的右上角,出口就是图片的左下角。
用ps看下右上角的入口点:
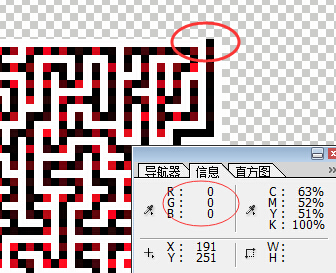
因此最开始通过getpixel(x, 0)[0]=0 找到入口点位置。
同理左下角出口点通过getpixel(x, 640)[0]=0 找到。
代码逻辑:
1.从入口点开始向四个方向找下个坐标点,找到后作为下一个入口点,并将当前像素点标白(255,255,255)
2.如果找到两个以上的下个出口坐标,即到了分岔口,备份之前的坐标队列,以此分岔口作为新的入口点,
3.如果未找到出口,则退回到上个分岔口继续查找。
最后生成的图片可以看到完成的迷宫路径:

显然这还不是谜底,在仔细观察迷宫的路径,可以发现每个一个像素点,路径上的颜色就会变化,
将这些像素点的R通道数据用二进制写到文件,打开可以发现前两位是PK ,那么这些信息其实是构成了一个ZIP文件。
更改后缀,解压,里面有两个文件,maze.jpg和mybroken.zip,其中maze.jpg图片上的lake就是谜底了。
完整代码:
def ambiguity():
import Image
org_img = Image.open("img/maze.png").getdata()
org_img_size = org_img.size
new_img = Image.new("RGBA", org_img_size, "black")
start_pos, end_pos = None, None
start_pos_count, end_pos_count = 0, 0
for x in range(org_img_size[0]):
if org_img.getpixel((x, 0))[0] == 0:
start_pos = (x, 0)
start_pos_count += 1
if org_img.getpixel((x, org_img_size[1]-1))[0] == 0:
end_pos = (x, org_img_size[1]-1)
end_pos_count += 1
if start_pos is None or end_pos is None or start_pos_count != 1 or end_pos_count != 1:
print "[error] : get start pos or end pos error!"
return False
print "[*] start_pos: %s and end_pos: %s" % (start_pos, end_pos)
path = []
whole_path = []
# 右 下 左 上
dire = [(1, 0), (0, 1), (-1, 0), (0, -1)]
wall = (255,)*4
while start_pos != end_pos:
org_img.putpixel(start_pos, wall)
flag = 0
new_pos = start_pos
for offset in dire:
try:
pp = (start_pos[0]+offset[0], start_pos[1]+offset[1])
if org_img.getpixel(pp) != wall:
flag += 1
new_pos = pp
except Exception, e:
print str(e)
pass
# 未找到下个出口
if flag == 0:
if not path:
path = whole_path.pop()
continue
start_pos = path[0]
path = []
# 分岔口,找到多个像素点,备份之前的坐标队列,以此分岔口作为新的入口点
elif flag > 1:
whole_path.append(path)
path = [start_pos]
start_pos = new_pos
# 找到唯一出口,flag = 1
else:
path.append(start_pos)
start_pos = new_pos
path.append(start_pos)
whole_path.append(path)
org_img = Image.open("img/maze.png").getdata()
data = []
for path in whole_path:
for k in path:
new_img.putpixel(k, wall)
data.append(org_img.getpixel(k)[0])
out = open("files/out24.zip", "wb")
for i in data[1::2]:
out.write(chr(i))
out.close()
new_img.save("img/out24.png")该题解迷宫逻辑参考PythonChallenge 挑战之路 Level-24
http://www.pythonchallenge.com/pc/hex/lake.html

谷歌大法好:
这是一幅拼图模样的图片,根据网页源码里的提示can you see the waves?,这一关还要用到wave模块。
把URL后缀改为lake1.wav,lake2.wav,…,lake25会得到25个wav文件。
每个wav文件为10800字节,将三个作为一个像素,可得到一张10800/3=60x60大小的图片。
这25个wav文件对应着刚才的25块拼图,把这25个wav文件的内容依次拼起来,会得到一张300x300大小的图片。
def lake():
from PIL import Image
import requests
import base64
import StringIO
import wave
headers = {
"Authorization": "Basic %s" % base64.encodestring("butter:fly").replace("\n", "")
}
wave_url = 'http://www.pythonchallenge.com/pc/hex/lake%i.wav'
new_img = Image.new('RGB', (300, 300))
for i in range(25):
print "%i/%i" % (i + 1, 25)
wave_content = requests.get(wave_url % (i + 1), headers=headers).content
data = wave.open(StringIO.StringIO(wave_content))
patch = Image.fromstring('RGB', (60, 60), data.readframes(data.getnframes()))
pos = (60 * (i % 5), 60 * (i / 5))
new_img.paste(patch, pos)
new_img.save("img/out25.jpg")
最终得到的图片中单词为最后答案:decent

http://www.pythonchallenge.com/pc/hex/decent.html

看网页源码中的提示:
1.be a man - apologize!
2.you've got his e-mail
3.Hurry up, I'm missing the boat提示让你先发邮件去道歉,邮箱哪里来,看19关的源码中有段没有用到的记录:
From: leopold.moz@pythonchallenge.com
Subject: what do you mean by "open the attachment?"
Mime-version: 1.0
Content-type: Multipart/mixed; boundary="===============1295515792=="
It is so much easier for you, youngsters.
Maybe my computer is out of order.
I have a real work to do and I must know what's inside!
...找到邮箱leopold.moz@pythonchallenge.com,要道歉,发送内容是什么?
看23关源码中没有用到的记录:
TODO: do you owe someone an apology? now it is a good time to
tell him that you are sorry. Please show good manners although
it has nothing to do with this level.现在就可以去给leopold.moz@pythonchallenge.com发送内容为sorry的邮件。
python发邮件模块网上很多,就几行代码,这里我直接用我邮箱发,然后收到回复:
从回复的邮件里得到了一个MD5值:bbb8b499a0eef99b52c7f13f4e78c24b以及它提到的broken.zip文件。这个解压文件在24关中得到,在解压的时候会提示CRC效验失败,也就是说缺少部分数据。但实际上用7z解压时候是可以解压出文件的。
但正常的过程应该是这个MD5值应该就是那个broken.zip的MD5值,需要将原文件的每个字节枚举看得到的MD5值是否为该MD5值,从而得到正确的文件。
def decent():
import hashlib
f_content = open("files/mybroken.zip", "rb").read()
for i in range(len(f_content)):
for j in range(256):
new_content = "".join([f_content[:i], chr(j), f_content[i+1:]])
if hashlib.md5(new_content).hexdigest() == "bbb8b499a0eef99b52c7f13f4e78c24b":
open("files/mybroken_new.zip", "wb").write(new_content)
print "offset %d -> %d" % (i, j)
>>> offset 1234 -> 168最后解压正确的zip文件得到一张图片

将得到的单词speed和提示Hurry up,I'm missing the boat组合起来得到下关答案speedboat
http://www.pythonchallenge.com/pc/hex/speedboat.html

谷歌大法好,要利用调色板这些东西,调色板可参考调色板palette详解
首先查看源码,将zigzag.gif下载下来

这时候每个像素的上的信息是调色板的索引号,然后就需要用实际的颜色替换索引号得到等价的图片信息。然后将这些数据与原图片信息对比,将不同的坐标点标记颜色,如新建一个黑底图片标白,最后得到一张图片。

图片左边是not,右边是word,下边是busy?,中间是钥匙,合起来是not key word。
然后将两个图片不相同的字节放在一起,最后经过颜色替换索引号得到的图片不同的数据得到一个bz压缩文件,解压出来并找到那些关键字里面哪些不是key word打印出,最后得到答案。
def speedboat():
import Image
import string
import bz2
import keyword
img = Image.open("img/zigzag.gif")
img_content = img.tostring()
img_plt = img.palette.getdata()[1][::3]
trans = string.maketrans("".join([chr(i) for i in range(256)]), img_plt)
img_tran = img_content.translate(trans)
# compare
diff = ["", ""]
img = Image.new("1", img.size, 0)
for i in range(1, len(img_content)):
if img_content[i] != img_tran[i-1]:
diff[0] += img_content[i]
diff[1] += img_tran[i-1]
img.putpixel(((i-1) % img.size[0], (i-1)/img.size[0]), 1)
img.save("img/out27.png")
text = bz2.decompress(diff[0])
# extract key
for i in text.split():
if not keyword.iskeyword(i):
print i
>>> ../ring/bell.html
repeat
switch
repeat
../ring/bell.html
../ring/bell.html
../ring/bell.html
...得到28关链接为http://www.pythonchallenge.com/pc/ring/bell.htm
账户名:repeat, 密码:switch
接上边继续斗智斗勇中。越来越觉得智商不够用了。。
http://www.pythonchallenge.com/pc/return/5808.html
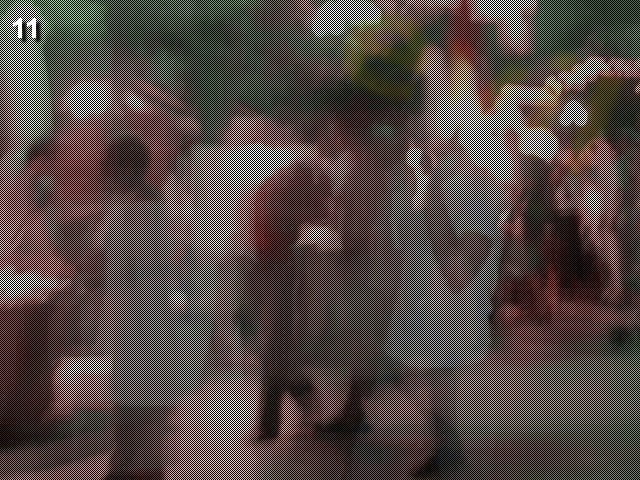
题目只有一张模糊的图片,源码也没什么提示,看页面title为odd even.
猜测这张模糊的图片是否是将两张图片合成的,因此将其奇偶坐标分离开.
分离坐标有四种情况,(odd, odd),(odd, even),(even, odd),(even, even).
我这里取双奇偶坐标(odd, odd)和(even, even).
在PIL库中,使用load函数的效果比使用putpixel和getpixel更高效,因此选择使用load函数.
def odd_even():
from PIL import Image
im = Image.open("img/python-challenge-11.jpg")
w, h = im.size
imgs = [Image.new(im.mode, (w / 2, h / 2)) for i in xrange(2)]
imgs_load = [img.load() for img in imgs]
org = im.load()
for i in xrange(w):
for j in xrange(h):
if (i + j) % 2 == 0:
org_pos = (i, j)
new_pos = (i / 2, j / 2)
imgs_load[i % 2][new_pos] = org[org_pos]
[imgs[i].save('img/python-challenge-11-%d.jpg' % i) for i in xrange(2)]
最后生成的两张图片是一样的
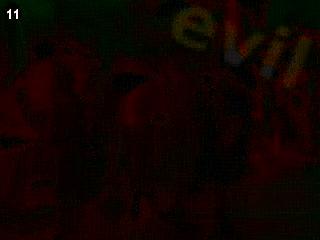
显示的单词evil即为答案。
http://www.pythonchallenge.com/pc/return/evil.html

一张没有什么异常的图片,查看下源码,注意看图片名字,evil1.jpg,这里应该尝试下evil2.jpg了。
evil2.jpg -> not jpg –gfx
evil3.jpg -> no more evils…
evil4.jpg -> Bert is evil! go back!(只在ie中可看到)
根据这些提示,先将evil2.jpg改为evil2.gfx,得到这个文件
GFX文件格式:GFX是一套跨平台的图形生成包,是一种可用于交互的图形格式,详情百度下。
到这里就没有思路了,看了下提示才知道,原来原图那人把扑克牌分成5堆,要把那个gfx文件用分牌的方式分成5个文件。
gfx的第一个字节给第一个文件,第二个字节给第二个文件,第三个字节给第三个文件,第四个字节给第四个文件,第五个字节给第五个文件,第六个字节给第一个文件……
def evil():
f = open('files/evil2.gfx', 'rb+')
content = f.read()
f.close()
for i in xrange(5):
f = open('files/evil2-%d.jpg' % i, 'wb+')
f.write(content[i::5])
f.close()最后得到5张图片连接起来即为结果:disproportional

http://www.pythonchallenge.com/pc/return/disproportional.html

这个页面显示了一个电话按键,并且标题为call him,很明显是要拨打一个电话号码。
图片最下边提示phone that evil,再回头看那个evil4.jpg的提示,Bert is evil! go back!
所以是要打电话给Bert,怎么打,不可能用自己手机打吧!然后在页面到处点点,一不小心点到了5就进去了。
进入页面:http://www.pythonchallenge.com/pc/phonebook.php
这是什么鬼,止步于此,开始度娘。。。
xmlrpc是使用http协议做为传输协议的rpc机制,使用xml文本的方式传输命令和数据blablabla…
反正就是要用到python的xmlrpclib模块来连接这个php页面,然后查看其方法,其中有个名为phone方法就是答案。
def disproportional():
import xmlrpclib
xml_rpc = xmlrpclib.ServerProxy("http://www.pythonchallenge.com/pc/phonebook.php")
print xml_rpc.system.listMethods()
print xml_rpc.system.methodHelp('phone')
print xml_rpc.phone('Bert')
>>> ['phone', 'system.listMethods', 'system.methodHelp', 'system.methodSignature', 'system.multicall', 'system.getCapabilities']
Returns the phone of a person
555-ITALY最后输入555-ITALY.html不行。。改为ITALY.html提示SMALL letters。。好吧。。italy.html
http://www.pythonchallenge.com/pc/return/italy.html

所有提示信息:
根据网页标题的提示:walk around
网页源码的提示:100*100 = (100+99+99+98) + (...
下边那张图wire.png点开标题为10000*1先验证序列公式
# 100*100 = (100+99+99+98) + (...
items = [i + i-1 + i-1 + i-2 for i in xrange(100, 1, -2)]
items_value = reduce(lambda x, y: x+y, items)
print "%d %d" % (len(items), items_value)
>>> 50 10000可知该序列公式是正确的。
10000x1 = 100x100是否要重新组图,按照这个思路把10000个像素重组
from PIL import Image
org_img = Image.open('img/wire.png')
org_data = list(org_img.getdata())
res_img = Image.new(org_img.mode, (100, 100))
res_data = res_img.load()
org_index = 0
for i in xrange(100):
for j in xrange(100):
res_data[j, i] = org_data[org_index]
org_index += 1
res_img.save("img/wire-0.png")最开始是按照先行后列的方式重组发现图片是反的,然后按照先列后行的方式重组,得到一个图片。

万分欣喜,进入bit.html页面就傻了:you took the wrong curve.
真是个悲伤的故事。。。
下边就完全没有任何头绪,只要又要借助度娘了,最后得到的解题思路是:
将10000x1的那张图片按照序列化的格式进行重新生成100x100的图片,生成的逻辑是:
按照图片面包的方向,从右边开始,外向内绕圈圈,
先向一个方向走100个像素,然后转90度,走99个像素,再转90度,再走99个像素,再转90度,再走98个像素,这样就完成了一个圈。
def italy():
from PIL import Image
# 100*100 = (100 + 99 + 99 + 98)+(...
items = [[i, i-1, i-1, i-2] for i in xrange(100, 1, -2)]
org_img = Image.open('img/wire.png')
org_data = list(org_img.getdata())
new_img = Image.new(org_img.mode, (100, 100))
new_data = new_img.load()
index = 0
x = y = 0
for item in items:
for j in xrange(item[0]):
new_data[x, y] = org_data[index]
x += 1
index += 1
x -= 1
for j in xrange(item[1]):
new_data[x, y] = org_data[index]
y += 1
index += 1
y -= 1
for j in xrange(item[2]):
new_data[x, y] = org_data[index]
x -= 1
index += 1
x += 1
for j in xrange(item[3]):
new_data[x, y] = org_data[index]
y -= 1
index += 1
y += 1
new_img.save('img/wire-cat.png')最后得到了一张图片

然后输入cat.html进入页面,出现了两只猫的图片,并有一段说明:
and its name is uzi. you’ll hear from him later.
替换为uzi.html进入下一题,uzi不是小狗吗 = =!
http://www.pythonchallenge.com/pc/return/uzi.html

先找到所有有用的提示:
网页源码
he ain’t the youngest, he is the second # 应该是找到一个年龄列表中第二年轻的
buy flowers for tomorrow # 结合1月26日应该是说明天即1月27日有事件发生
结合以上信息
应该是找到1**6年中的所有闰年,且2月29日为周一的时间中第二个年轻的年份,
然后加上1月27日得到一个事件时间,这个时间和一个人有关系。
# run in python 3.0+
def uzi():
from datetime import datetime
def get_week_day(year_, mouth_, day_):
return datetime(year_, mouth_, day_).strftime("%w")
leap_years = [i for i in range(1006, 1997, 10) if (i % 4 == 0 and i % 100 != 0) or i % 400 == 0]
# print (leap_years)
match_year = [y for y in leap_years if get_week_day(y, 2, 29) == "0"]
print (match_year)
print ("%d-01-17" % match_year[-2])
>>> [1176, 1356, 1576, 1756, 1976]
1756-01-17由于python2.7版本中the datetime strftime() methods require year >= 1900,
因此该代码需要运行在python3.0+
最后百度关键词1756年1月27日,著名的音乐大师沃尔弗于格·莫扎特(mozart),诞生于奥地利查尔茨堡。
诞生于,诞生啊。。其实最初我以为送花是第二天有人挂掉了去拜祭。。面壁思过中。。。
http://www.pythonchallenge.com/pc/return/mozart.html

页面标题提示:let me get this straight
观察图片将粉色的线条对齐排成一列,即将每行像素点循环左移知道粉色点位于最左边。
其中图片模式为索引像素模式,用ps查看得到粉色Idx=195,对应RGB=(255, 0, 255)。
def mozart():
from PIL import Image
org_img = Image.open('img/mozart.gif')
org_size = org_img.size
org_data = list(org_img.getdata())
# new_img = Image.new(org_img.mode, org_size)
new_img = org_img.copy()
new_data = new_img.load()
for y in range(org_size[1]):
line_pixels = org_data[org_size[0] * y: org_size[0] * (y + 1)]
pink_index = line_pixels.index(195)
for x, pixel in enumerate(line_pixels[pink_index:] + line_pixels[:pink_index]):
new_data[x, y] = pixel
new_img.save("img/romance.gif")最后生成答案图片

http://www.pythonchallenge.com/pc/return/romance.html

做这个题请自觉开启自虐模式,不要问我为什么,我只想静静。
页面标题:eat? 看下源代码图片名字为cookies.jpg
cookies点心?cookie?打开chrome控制台输入alert(document.cookie)
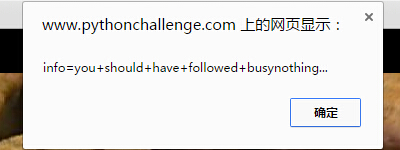
you should have followed busynothing…
结合图片左下角linkedlist页面的图片,想到之前遍历时候找的每个页面,这个应该是遍历找每个页面的cookie信息了。
初步验证,先进入linkedlist的第一个节点:
http://www.pythonchallenge.com/pc/def/linkedlist.php?busynothing=12345
页面内容:
If you came here from level 4 - go back!
You should follow the obvious chain...
and the next busynothing is 44827大概意思是说这个界面如果你是从第四关跳进去的话请返回,显示的关键字会是nothing而非busynothing。
因此一定要从第一个节点进入,不要从linkedlist.php点击图片进入,否则获取不到cookie信息。
弹出的cookie信息为:info=B
第二个节点:http://www.pythonchallenge.com/pc/def/linkedlist.php?busynothing=44827
弹出的cookie信息为:info=Z
是不是有点眼熟,回头找找第8关的BZ2压缩。。
之后是写代码之路,其中cookie模块参考:urllib2模块、cookielib模块
遍历完cookie信息后得到字符串:
BZh91AY%26SY%94%3A%E2I%00%00%21%19%80P%81%11%00%AFg%9E%A0+%00hE%3DM%B5%23%D0%D4%D1%E2%8D%06%A9%FA%26S%D4%D3%21%A1%EAi7h%9B%9A%2B%BF%60%22%C5WX%E1%ADL%80%E8V%3C%C6%A8%DBH%2632%18%A8x%01%08%21%8DS%0B%C8%AF%96KO%CA2%B0%F1%BD%1Du%A0%86%05%92s%B0%92%C4Bc%F1w%24S%85%09%09C%AE%24看看格式应该是转义过的,调用urllib转义函数得到结果:
BZh91AY&SY\x94:\xe2I\x00\x00!\x19\x80P\x81\x11\x00\xafg\x9e\xa0 \x00hE=M\xb5#\xd0\xd4\xd1\xe2\x8d\x06\xa9\xfa&S\xd4\xd3!\xa1\xeai7h\x9b\x9a+\xbf`"\xc5WX\xe1\xadL\x80\xe8V<\xc6\xa8\xdbH&32\x18\xa8x\x01\x08!\x8dS\x0b\xc8\xaf\x96KO\xca2\xb0\xf1\xbd\x1du\xa0\x86\x05\x92s\xb0\x92\xc4Bc\xf1w$S\x85\t\tC\xae$\x90这个看着就很熟悉了,调用bz2进行解压
is it the 26th already? call his father and inform him that "the flowers are on their way". he'll understand.这个结果看的也是格外的忧伤,竟然还有这么多的坑。。看看26th说的是莫扎特,查下莫扎特的老爹为Leopold。
试试Leopold.html,404啊,404!!!
再仔细看,call his father,打电话,电话!!!
调用13关的代码Bert改为Leopold返回555-VIOLIN
参考13关去数字改小写地址为violin.html,竟然还有,呵呵哒。。。
no! i mean yes! but ../stuff/violin.php.再改将上级目录改为/stuff/violin.php
即http://www.pythonchallenge.com/pc/stuff/violin.php
看到图片我以为终于完了,仔细一看,编号呢,没编号肯定还是个坑啊,我内心几乎是崩溃的。。

看下页面提示标题:it’s me. what do you want?
返回页面也没有什么其他信息,答案在哪里?!?!?
想想这个题主题是cookie,回头再看上边的解压出来的提示信息,后半句还没有用到。
inform him that “the flowers are on their way”
翻译是告诉他鲜花已经来路上,暗示要给他携带信息。
也就是说要带上info=“the flowers are on their way"消息去访问这个页面!
cj._cookies.values()[0]['/']['info'].value = 'the+flowers+are+on+their+way'
violin_source = opener.open('http://www.pythonchallenge.com/pc/stuff/violin.php').read()
print violin_source打印出来的页面:
<html>
<head>
<title>it's me. what do you want?</title>
<link rel="stylesheet" type="text/css" href="../style.css">
</head>
<body>
<br><br>
<center><font color="gold">
<img src="leopold.jpg" border="0"/>
<br><br>
oh well, don't you dare to forget the balloons.</font>
</body>
</html>终于出结果了,balloons,感觉已经可以开始google大法了QAQ。。
完整逻辑代码,其中略掉level13的代码:
def romance():
import urllib2
import cookielib
import urllib
cj = cookielib.CookieJar()
handler = urllib2.HTTPCookieProcessor(cj)
opener = urllib2.build_opener(handler)
base_url = "http://www.pythonchallenge.com/pc/def/linkedlist.php"
param = "12345"
times = 1
info = []
while True:
try:
url = "?busynothing=".join([base_url, param])
page_source = opener.open(url).read()
param = re.findall("and the next busynothing is ([0-9]+)", page_source)[0]
ck = cj._cookies.values()[0]['/']['info'].value
info.append(ck)
print "%d -> %s -> %s" % (times, param, ck)
times += 1
# 匹配不到跳到异常
except IndexError:
print "the end is : %d" % times
break
message = "".join(info)
print message
# 转义
message = urllib.unquote_plus(message)
result = message.decode("bz2")
print result
# ---level 13 code ---#
# url = "?busynothing=".join([base_url, param])
# page_source = opener.open(url).read()
cj._cookies.values()[0]['/']['info'].value = 'the+flowers+are+on+their+way'
violin_source = opener.open('http://www.pythonchallenge.com/pc/stuff/violin.php').read()
print violin_sourcehttp://www.pythonchallenge.com/pc/return/balloons.html

页面标题:can you tell the difference?
明显的两张图片亮度不同,英文brightness.
进入该页面后再看源码提示:maybe consider deltas.gz
将该文件下载下来,解压后看到delta.txt里是分为两栏的16进制数据。
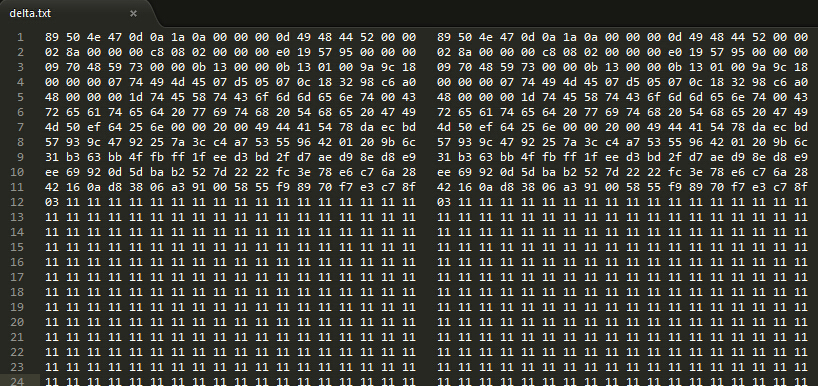
仔细对比两边内容,发现有部分重复的,也就是通过比较两栏内容,来分发字节。
左边特有的,右边特有的,公共部分,分别生成三张图片。
这里需要用到difflib模块来进行数据处理。
def balloons():
import difflib
f_delta = open('files/delta.txt', 'r+')
deltas = f_delta.read().split('\n')
f_delta.close()
left_data = []
right_data = []
for line in deltas:
left_data.append(line[:53]+'\n')
right_data.append(line[56:]+'\n')
diff = difflib.Differ()
cmp_result = list(diff.compare(left_data, right_data))
left_pic = open('img/18-left-diff.png', 'wb')
right_pic = open('img/18-right-diff.png', 'wb')
common_pic = open('img/18-common.png', 'wb')
for line in cmp_result:
bytes = [(chr(int(h, 16))) for h in line[2:].split()]
if line.startswith('-'):
map(left_pic.write, bytes)
elif line.startswith('+'):
map(right_pic.write, bytes)
elif line.startswith(' '):
map(common_pic.write, bytes)
right_pic.close()
left_pic.close()
common_pic.close()最后生成的三张图片

进入http://www.pythonchallenge.com/pc/hex/bin.html
用户名:butter 密码:fly
http://www.pythonchallenge.com/pc/hex/bin.html
看网页源码,base64加密一段音频数据indian.wav
def hex_bin():
import base64
headers = {
"Authorization": "Basic YnV0dGVyOmZseQ=="
}
page_source = requests.get("http://www.pythonchallenge.com/pc/hex/bin.html", headers=headers).text
wav_data = re.findall(r"base64([\s\S]+?)--", page_source)[0].strip("\n")
indian = open("files/indian.wav", "wb")
indian.write(base64.b64decode(wav_data))
indian.close()打开生成的音频文件,有个怪怪的声音:sorry..
打开sorry界面显示:what are you apologizing for
再回头看看图片,大陆和海洋的颜色是反转的,尝试将音频每一帧反转
def hex_bin():
import base64
import wave
headers = {
"Authorization": "Basic YnV0dGVyOmZseQ=="
}
page_source = requests.get("http://www.pythonchallenge.com/pc/hex/bin.html", headers=headers).text
wav_data = re.findall(r"base64([\s\S]+?)--", page_source)[0].strip("\n")
indian = open("files/indian.wav", "wb")
indian.write(base64.b64decode(wav_data))
indian.close()
indian = wave.open("files/indian.wav", "rb")
reverse = wave.open("files/indian-reverse.wav", "wb")
reverse.setnchannels(1)
reverse.setframerate(indian.getframerate())
reverse.setsampwidth(indian.getsampwidth())
for i in range(indian.getnframes()):
reverse.writeframes(indian.readframes(1)[::-1])
indian.close()
reverse.close()播放下听听,You are a idiot ha ha ha ha ha ha …..
进入idiot.html显示:Now you should apologize,Continue to the next level进入下一关。
http://www.pythonchallenge.com/pc/hex/idiot2.html

页面标题:go away!
图片下边:but inspecting it carefully is allowed.
大概意思是围栏那边的是私有财产,请离开私有财产,虽然不允许进入,但可以观察。
没有一点思路,谷歌大法好,抓下图片包看下请求头信息:
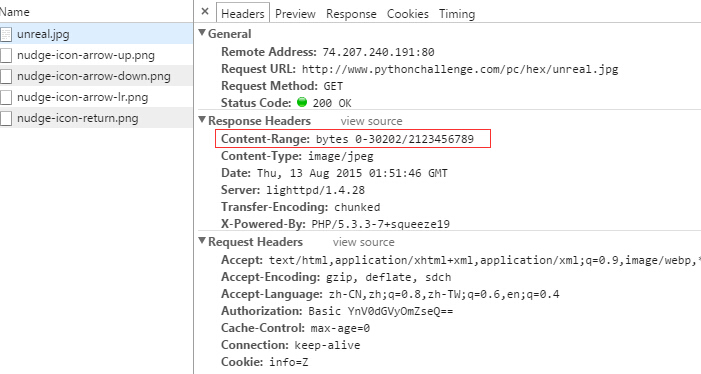
这里的Content-Range的值是: bytes 0-30202/2123456789,这看上去与所谓的“断点续传”十分相似。
从这个信息知道原始图片大小有2123456789个字节,但是目前的“unreal.jpg” 只有前面的30202 个字节,这就说明看到的“unreal.jpg”并不完整。
那就先要把“unreal.jpg”下载完全才行。
要指定请求的字节范围,需要在请求中加入一个叫Range的头,基本形式是“Range: bytes=1000-2345”。
headers = {
"Authorization": "Basic YnV0dGVyOmZseQ==",
"Range": "bytes=30203-"
}
img = requests.get("http://www.pythonchallenge.com/pc/hex/unreal.jpg", headers=headers)
print img.text
>>> u"Why don't you respect my privacy?\n"服务器返回了有意义的信息,因此写个遍历将所有信息打印出来。
def idiot2():
pic_url = "http://www.pythonchallenge.com/pc/hex/unreal.jpg"
next_range = 30203
end_range = 2123456789
while next_range <= end_range:
headers = {
"Authorization": "Basic YnV0dGVyOmZseQ==",
"Range": "bytes=%d-" % next_range
}
img = requests.get(pic_url, headers=headers)
if img.status_code == 206:
print "range : %d -> %s" % (next_range, img.text)
content_range = img.headers.get("Content-Range")
next_range = re.findall(r"bytes.+-(\d+)/", content_range)[0]
next_range = int(next_range) + 1
else:
break
>>>
range : 30203 -> Why don't you respect my privacy?
range : 30237 -> we can go on in this way for really long time.
range : 30284 -> stop this!
range : 30295 -> invader! invader!
range : 30313 -> ok, invader. you are inside now.
Process finished with exit code 0信息中反复提到的入侵者invader,尝试更换下网址为invader.html。
页面显示:Yes! that’s you! 这提示,然并卵。。。
从前边入侵不行,那就从后边入侵试试?
将代码中next_range改为2123456789打印出来为:
esrever ni emankcin wen ruoy si drowssap eht将其反过来
end_text = "esrever ni emankcin wen ruoy si drowssap eht"
result = [text_[::-1] for text_ in end_text.split()[::-1]]
print " ".join(result)
>>> the password is your new nickname in reverse通过读取Content-Range再入侵前一个得到信息:
range : 2123456743 -> and it is hiding at 1152983631.通过这条信息得之其隐藏在1152983631,入侵之后得到pk开头的数据即zip包。
将其下载下来,解压需要密码,密码看前边的提示信息:
the password is your new nickname in reverse
新绰号即为入侵者invader,反过来为redavni。
解压过后生成两个文件,package.pack和readme.txt,打开readme文件内容为:
Yes! This is really level 21 in here.
And yes, After you solve it, you'll be in level 22!
Now for the level:
* We used to play this game when we were kids
* When I had no idea what to do, I looked backwards.已经进入了level 21.
完整代码:
def idiot2():
pic_url = "http://www.pythonchallenge.com/pc/hex/unreal.jpg"
next_range = 30203
end_range = 2123456789
while next_range <= end_range:
headers = {
"Authorization": "Basic YnV0dGVyOmZseQ==",
"Range": "bytes=%d-" % next_range
}
img = requests.get(pic_url, headers=headers)
if img.status_code == 206:
print "range : %d -> %s" % (next_range, img.text)
content_range = img.headers.get("Content-Range")
next_range = re.findall(r"bytes.+-(\d+)/", content_range)[0]
next_range = int(next_range) + 1
else:
break
# reverse
cur_range = 2123456789
end_range = 2123456789
is_download = False
while cur_range <= end_range:
headers = {
"Authorization": "Basic YnV0dGVyOmZseQ==",
"Range": "bytes=%d-" % cur_range
}
img = requests.get(pic_url, headers=headers)
if img.status_code == 206:
if is_download is True:
open("files/invader.zip", "wb").write(img.content)
break
print "range : %d -> %s" % (cur_range, img.text)
content_range = img.headers.get("Content-Range")
cur_range = re.findall(r"bytes (\d+)-", content_range)[0]
cur_range = int(cur_range) - 1
img_text = img.text
result = [text_[::-1] for text_ in img_text.split()[::-1]]
print " ".join(result)
elif img.status_code == 416:
cur_range = img_text.split()[-1].strip(".")
cur_range = int(cur_range)
is_download = True最近闲下来了四处看资料,然后找到了这个python challenge网页闯关游戏。
这个游戏需要通过一些提示找出下一关的网页地址,链接:http://www.pythonchallenge.com/
题目出的也是充满想象力,斗智斗勇中。。。
解题代码整理在我的 github
http://www.pythonchallenge.com/pc/def/0.html

# 2的38次幂
def calc():
return 2 ** 38
>>> 274877906944Lhttp://www.pythonchallenge.com/pc/def/274877906944.html

通过图片可知道,所有字符右移两位即可。
def map_():
first_alpha = chr(ord("m") + 2)
second_alpha = chr(ord("a") + 2)
third_alpha = chr(ord("p") + 2)
return "".join([first_alpha, second_alpha, third_alpha])
>>> ocrhttp://www.pythonchallenge.com/pc/def/ocr.html

查找出现次数最少的字符,先是统计出所有字符出现的次数,然后获取出现次数最早的,要注意按照原来顺序排列。
def ocr():
stats = {}
req = requests.get("http://www.pythonchallenge.com/pc/def/ocr.html")
page_source = req.text
mess_pattern = re.compile(r"(%%[\s\S]+)-->", re.IGNORECASE)
mess_content = mess_pattern.findall(page_source)[0]
# print mess_content
for character in mess_content:
if character in stats:
stats[character] += 1
else:
stats[character] = 1
for key_, value_ in stats.items():
print "%s -> %d" % (key_, value_)
# a e i l q u t y
return "".join(re.findall(r"[a-z]+", mess_content))
>>> u'equality'http://www.pythonchallenge.com/pc/def/equality.html

小写字符两边有三个大写字母,格式为aAAAaAAAa
AAAaAAA这种匹配是错误的,要保证两边都是三位大写字母
def equality():
req = requests.get("http://www.pythonchallenge.com/pc/def/equality.html")
page_source = req.text
mess_pattern = re.compile(r"kAewtloYgc[\s\S]+", re.IGNORECASE)
mess_content = mess_pattern.findall(page_source)[0]
return "".join(re.findall(r"[a-z]{1}[A-Z]{3}([a-z]{1})[A-Z]{3}[a-z]{1}", mess_content))
>>> u'linkedlist'http://www.pythonchallenge.com/pc/def/linkedlist.php

点击图片会有提示,然后更换链接参数继续,大概200多次即可得到答案。
其中正则不能只写"[0-9]+“,中间有陷阱:
There maybe misleading numbers in the text. One example is 82683\. Look only for the next nothing and the next nothing is 63579完整代码如下:
def linkedlist(times=1, param="123456"):
try:
url = "?nothing=".join(["http://www.pythonchallenge.com/pc/def/linkedlist.php", param])
page_source = requests.get(url).text
next_param = re.findall("and the next nothing is ([0-9]+)", page_source)[0]
print "%d -> %s" % (times, next_param)
times += 1
linkedlist(times, next_param)
# 匹配不到跳到异常
except IndexError:
print "the right url is : %s" % url
return page_source
>>> the right url is : http://www.pythonchallenge.com/pc/def/linkedlist.php?nothing=66831
peak.htmlhttp://www.pythonchallenge.com/pc/def/peak.html

这关估计卡了不少人,从页面源码只能得到banner.p文件地址,即http://www.pythonchallenge.com/pc/def/banner.p
跟我一样没有用过pickle模块的一般都解不出来,看到文件内容也是没有头绪的,通过上网查了资料才知道如何解题。
# pickle模块的使用
def peak():
import pickle
page_source = requests.get("http://www.pythonchallenge.com/pc/def/peak.html").text
banner_name = re.findall(r"", page_source)[0]
banner_url = "".join(["http://www.pythonchallenge.com/pc/def/", banner_name])
banner_content = requests.get(banner_url).text
# print banner_content
banner_obj = pickle.loads(banner_content)
for list_ in banner_obj:
print "".join([tuple_[0] * tuple_[1] for tuple_ in list_])
>>>
##### #####
#### ####
#### ####
#### ####
#### ####
#### ####
#### ####
#### ####
### #### ### ### ##### ### ##### ### ### ####
### ## #### ####### ## ### #### ####### #### ####### ### ### ####
### ### ##### #### ### #### ##### #### ##### #### ### ### ####
### #### #### ### ### #### #### #### #### ### #### ####
### #### #### ### #### #### #### #### ### ### ####
#### #### #### ## ### #### #### #### #### #### ### ####
#### #### #### ########## #### #### #### #### ############## ####
#### #### #### ### #### #### #### #### #### #### ####
#### #### #### #### ### #### #### #### #### #### ####
### #### #### #### ### #### #### #### #### ### ####
### ## #### #### ### #### #### #### #### #### ### ## ####
### ## #### #### ########### #### #### #### #### ### ## ####
### ###### ##### ## #### ###### ########### ##### ### ######http://www.pythonchallenge.com/pc/def/channel.html

一张拉链图片,看了源码也没有任何提示,只知道是要捐赠。。。
再仔细看第一行, ,将html变zip
下载channel.zip文件,链接:http://www.pythonchallenge.com/pc/def/channel.zip
下载完成后解压,和第四题一样,只不过多了文件遍历操作,遍历从任意文件开始都可以。
我这里从os.walk遍历到的文件列表中第一个文件开始遍历。
def channel():
import os
root_path = "D:\\downloads\\channel"
def linked_file(times=1, file_name="123456"):
try:
file_path = "\\".join([root_path, file_name])
file_content = open(file_path, "r+").read()
next_file_name = re.findall("Next nothing is ([0-9]+)", file_content)[0]
print "%d -> %s.txt" % (times, next_file_name)
times += 1
linked_file(times, "".join([next_file_name, ".txt"]))
# 匹配不到跳到异常
except IndexError:
print "the right link in file : %s" % file_name
print file_content
for root, dirs, files in os.walk(root_path):
for file_ in files:
linked_file(1, file_)
break
>>> the right link in file : 46145.txt
Collect the comments.坑爹的答案,让我收集注释,那么答案在哪里。。。
再仔细翻解压的文件,发现里边有个readme.txt !!!
welcome to my zipped list.
hint1: start from 90052
hint2: answer is inside the zip将代码中linkedfile(1, file)改为linked_file(1, "90052.txt”)
最后输出答案一样!!!
难道是我的解压方式不对?!?!
调用zipfile模块,使用ZipInfo类获取comment
def channel():
import zipfile
zf = zipfile.ZipFile("D:\\downloads\\channel.zip")
result = []
begin_file_name = "90052.txt"
while True:
z_info = zf.getinfo(begin_file_name)
f = zf.open(z_info)
f_content = f.read()
next_file_name = re.findall(r"Next nothing is ([0-9]+)", f_content)
f.close()
result.append(z_info.comment)
if next_file_name:
begin_file_name = "%s.txt" % next_file_name[0]
else:
break
print "".join(result)
>>>
****************************************************************
****************************************************************
** **
** OO OO XX YYYY GG GG EEEEEE NN NN **
** OO OO XXXXXX YYYYYY GG GG EEEEEE NN NN **
** OO OO XXX XXX YYY YY GG GG EE NN NN **
** OOOOOOOO XX XX YY GGG EEEEE NNNN **
** OOOOOOOO XX XX YY GGG EEEEE NN **
** OO OO XXX XXX YYY YY GG GG EE NN **
** OO OO XXXXXX YYYYYY GG GG EEEEEE NN **
** OO OO XX YYYY GG GG EEEEEE NN **
** **
****************************************************************
**************************************************************
将url改为hockey.html,竟然有小关卡!!!
it's in the air. look at the letters
赶紧开开脑洞,空气中是什么,氧气啊!
oxygen :)
http://www.pythonchallenge.com/pc/def/oxygen.html

这个题需要解析图片,之前没有接触到因此是查资料完成。
1.需要安装PIL库
2.截取黑白部分
3.将RGBA格式的像素每个像素值按照L8位黑白像素的格式转成一个acsii码值
4.将最后获得的答案转换为ASCII码
def oxygen():
from PIL import Image
img = Image.open("oxygen.png")
# left,top,right,bottom
box = (0, 43, 608, 52)
belt = img.crop(box)
# get a sequence object containing pixel values
pixels = belt.getdata()
print('mode: %s' % img.mode)
print('amount of pixel: %d' % len(pixels))
# print(pixels[0])
# convert mode RGBA to mode L
l_belt = belt.convert('L')
# get a sequence object containing pixel values
l_pixels = l_belt.getdata()
result = []
for i in range(0, 608, 7):
result.append(chr(l_pixels[i]))
print ''.join(result)
>>> smart guy, you made it. the next level is [105, 110, 116, 101, 103, 114, 105, 116, 121]最后将[105, 110, 116, 101, 103, 114, 105, 116, 121]转为ascii即为答案:integrity
http://www.pythonchallenge.com/pc/def/integrity.html

点击中间的蜜蜂弹出要求输入用户名和密码
然后看下源码,找到了用户名密码
un: 'BZh91AY&SYA\xaf\x82\r\x00\x00\x01\x01\x80\x02\xc0\x02\x00 \x00!\x9ah3M\x07<]\xc9\x14\xe1BA\x06\xbe\x084'
pw: 'BZh91AY&SY\x94$|\x0e\x00\x00\x00\x81\x00\x03$ \x00!\x9ah3M\x13<]\xc9\x14\xe1BBP\x91\xf08'看下加密字符串特征BZ开头,猜测是否为bz2压缩,尝试成功。
def integrity():
import bz2
un = 'BZh91AY&SYA\xaf\x82\r\x00\x00\x01\x01\x80\x02\xc0\x02\x00 \x00!\x9ah3M\x07<]\xc9\x14\xe1BA\x06\xbe\x084'
pw = 'BZh91AY&SY\x94$|\x0e\x00\x00\x00\x81\x00\x03$ \x00!\x9ah3M\x13<]\xc9\x14\xe1BBP\x91\xf08'
print ": ".join(["username", bz2.decompress(un)])
print ": ".join(["password", bz2.decompress(pw)])
>>>
username: huge
password: filehttp://www.pythonchallenge.com/pc/return/good.html

查看下源码找到最下边注释部分,和8题页面源码部分是不是很相似,应该是绘制图片的RGB值。
替换过去试试看,鼠标移动,发现浮现了一头牛的图案。
下边通过代码将这个图片完整的绘制出来。
def good():
from PIL import Image, ImageDraw
im = Image.new('RGB', (500, 500))
draw = ImageDraw.Draw(im)
headers = {
"Authorization": "Basic aHVnZTpmaWxl"
}
page_source = requests.get("http://www.pythonchallenge.com/pc/return/good.html", headers=headers).text
result = re.findall(r"first:\s([\s\S]+)second:\s([\s\S]+)-->", page_source)
if len(result) > 0 and len(result[0]) == 2:
first, second = result[0][0], result[0][1]
first_points = list(eval(first.replace("\n", "")))
second_points = list(eval(second.replace("\n", "")))
for i in range(0, len(first_points), 2):
draw.line(first_points[i:i + 4], fill='white')
for i in range(0, len(second_points), 2):
draw.line(second_points[i:i + 4], fill='white')
im.save('img/09.jpg')
最后打印出来:

看到牛先想到单词cow,然后进去试试看,发现有新的提示:
hmm. it's a male.
那就是公牛喽,换成bull,成功。
http://www.pythonchallenge.com/pc/return/bull.html

这个题的图片赫然就是我们绘制的那头牛哇,感觉萌萌哒。
看下边len(a[30])=? 要知道这个答案,肯定要得到a这个序列。
查看下页面源码,点开里边的sequence.txt内容为(点击牛也会跳出):
a = [1, 11, 21, 1211, 111221, 显然,要得到的答案就是这里了,下边找规律吧。
| index | look | say |
|---|---|---|
| 0 | . | 1 |
| 1 | 第0项有 1个1 | 11 |
| 2 | 第1项有 2个1 | 21 |
| 3 | 第2项有 1个2 1个1 | 1211 |
| 4 | 第3项有 1个1 1个2 2个1 | 111221 |
| 5 | . | . |
规律找到,编写代码如下:
def bull():
def get_next_item(str_item=""):
item = []
if len(str_item) == 0:
item.append("1")
elif len(str_item) > 0:
cur_list = list(str_item)
same_count = 1
if len(cur_list) == 1:
item.append("".join([str(same_count), cur_list[0]]))
elif len(cur_list) > 1:
for i in range(len(cur_list)):
if i + 1 >= len(cur_list):
item.append("".join([str(same_count), cur_list[i]]))
elif i + 1 < len(cur_list):
if cur_list[i] == cur_list[i+1]:
same_count += 1
else:
item.append("".join([str(same_count), cur_list[i]]))
same_count = 1
return "".join(item)
index = 0
cur_item = ""
while index < 31:
cur_item = get_next_item(cur_item)
index += 1
print "len(a[%d]) = %d" % (index-1, len(cur_item))
>>> len(a[30]) = 5808
网上看下别人的答案,找到一种更简单的实现方式,调用groupby函数,一行代码即可实现。
def bull_ex():
from itertools import groupby
a = '1'
for i in range(30):
a = ''.join(str(len(list(v))) + k for k, v in groupby(a))
print len(a)
