接上边继续斗智斗勇中。越来越觉得智商不够用了。。
python challenge 11
http://www.pythonchallenge.com/pc/return/5808.html
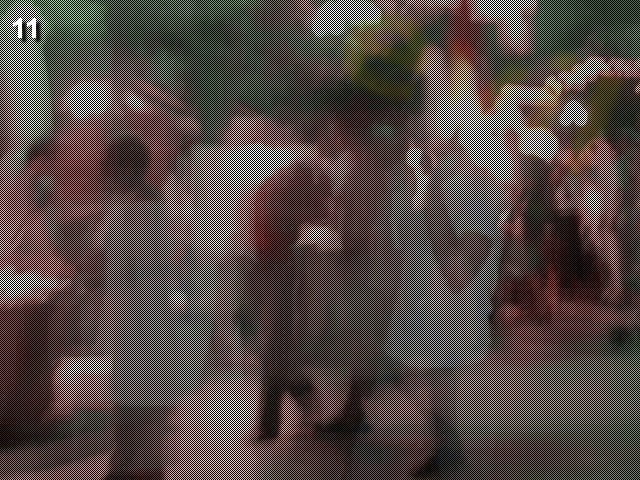
题目只有一张模糊的图片,源码也没什么提示,看页面title为odd even.
猜测这张模糊的图片是否是将两张图片合成的,因此将其奇偶坐标分离开.
分离坐标有四种情况,(odd, odd),(odd, even),(even, odd),(even, even).
我这里取双奇偶坐标(odd, odd)和(even, even).
在PIL库中,使用load函数的效果比使用putpixel和getpixel更高效,因此选择使用load函数.
def odd_even():
from PIL import Image
im = Image.open("img/python-challenge-11.jpg")
w, h = im.size
imgs = [Image.new(im.mode, (w / 2, h / 2)) for i in xrange(2)]
imgs_load = [img.load() for img in imgs]
org = im.load()
for i in xrange(w):
for j in xrange(h):
if (i + j) % 2 == 0:
org_pos = (i, j)
new_pos = (i / 2, j / 2)
imgs_load[i % 2][new_pos] = org[org_pos]
[imgs[i].save('img/python-challenge-11-%d.jpg' % i) for i in xrange(2)]
最后生成的两张图片是一样的
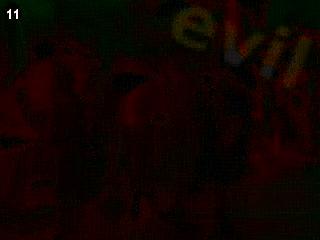
显示的单词evil即为答案。
python challenge 12
http://www.pythonchallenge.com/pc/return/evil.html

一张没有什么异常的图片,查看下源码,注意看图片名字,evil1.jpg,这里应该尝试下evil2.jpg了。
evil2.jpg -> not jpg –gfx
evil3.jpg -> no more evils…
evil4.jpg -> Bert is evil! go back!(只在ie中可看到)
根据这些提示,先将evil2.jpg改为evil2.gfx,得到这个文件
GFX文件格式:GFX是一套跨平台的图形生成包,是一种可用于交互的图形格式,详情百度下。
到这里就没有思路了,看了下提示才知道,原来原图那人把扑克牌分成5堆,要把那个gfx文件用分牌的方式分成5个文件。
gfx的第一个字节给第一个文件,第二个字节给第二个文件,第三个字节给第三个文件,第四个字节给第四个文件,第五个字节给第五个文件,第六个字节给第一个文件……
def evil():
f = open('files/evil2.gfx', 'rb+')
content = f.read()
f.close()
for i in xrange(5):
f = open('files/evil2-%d.jpg' % i, 'wb+')
f.write(content[i::5])
f.close()最后得到5张图片连接起来即为结果:disproportional

python challenge 13
http://www.pythonchallenge.com/pc/return/disproportional.html

这个页面显示了一个电话按键,并且标题为call him,很明显是要拨打一个电话号码。
图片最下边提示phone that evil,再回头看那个evil4.jpg的提示,Bert is evil! go back!
所以是要打电话给Bert,怎么打,不可能用自己手机打吧!然后在页面到处点点,一不小心点到了5就进去了。
进入页面:http://www.pythonchallenge.com/pc/phonebook.php
这是什么鬼,止步于此,开始度娘。。。
xmlrpc是使用http协议做为传输协议的rpc机制,使用xml文本的方式传输命令和数据blablabla…
反正就是要用到python的xmlrpclib模块来连接这个php页面,然后查看其方法,其中有个名为phone方法就是答案。
def disproportional():
import xmlrpclib
xml_rpc = xmlrpclib.ServerProxy("http://www.pythonchallenge.com/pc/phonebook.php")
print xml_rpc.system.listMethods()
print xml_rpc.system.methodHelp('phone')
print xml_rpc.phone('Bert')
>>> ['phone', 'system.listMethods', 'system.methodHelp', 'system.methodSignature', 'system.multicall', 'system.getCapabilities']
Returns the phone of a person
555-ITALY最后输入555-ITALY.html不行。。改为ITALY.html提示SMALL letters。。好吧。。italy.html
python challenge 14
http://www.pythonchallenge.com/pc/return/italy.html

所有提示信息:
根据网页标题的提示:walk around
网页源码的提示:100*100 = (100+99+99+98) + (...
下边那张图wire.png点开标题为10000*1先验证序列公式
# 100*100 = (100+99+99+98) + (...
items = [i + i-1 + i-1 + i-2 for i in xrange(100, 1, -2)]
items_value = reduce(lambda x, y: x+y, items)
print "%d %d" % (len(items), items_value)
>>> 50 10000可知该序列公式是正确的。
10000x1 = 100x100是否要重新组图,按照这个思路把10000个像素重组
from PIL import Image
org_img = Image.open('img/wire.png')
org_data = list(org_img.getdata())
res_img = Image.new(org_img.mode, (100, 100))
res_data = res_img.load()
org_index = 0
for i in xrange(100):
for j in xrange(100):
res_data[j, i] = org_data[org_index]
org_index += 1
res_img.save("img/wire-0.png")最开始是按照先行后列的方式重组发现图片是反的,然后按照先列后行的方式重组,得到一个图片。

万分欣喜,进入bit.html页面就傻了:you took the wrong curve.
真是个悲伤的故事。。。
下边就完全没有任何头绪,只要又要借助度娘了,最后得到的解题思路是:
将10000x1的那张图片按照序列化的格式进行重新生成100x100的图片,生成的逻辑是:
按照图片面包的方向,从右边开始,外向内绕圈圈,
先向一个方向走100个像素,然后转90度,走99个像素,再转90度,再走99个像素,再转90度,再走98个像素,这样就完成了一个圈。
def italy():
from PIL import Image
# 100*100 = (100 + 99 + 99 + 98)+(...
items = [[i, i-1, i-1, i-2] for i in xrange(100, 1, -2)]
org_img = Image.open('img/wire.png')
org_data = list(org_img.getdata())
new_img = Image.new(org_img.mode, (100, 100))
new_data = new_img.load()
index = 0
x = y = 0
for item in items:
for j in xrange(item[0]):
new_data[x, y] = org_data[index]
x += 1
index += 1
x -= 1
for j in xrange(item[1]):
new_data[x, y] = org_data[index]
y += 1
index += 1
y -= 1
for j in xrange(item[2]):
new_data[x, y] = org_data[index]
x -= 1
index += 1
x += 1
for j in xrange(item[3]):
new_data[x, y] = org_data[index]
y -= 1
index += 1
y += 1
new_img.save('img/wire-cat.png')最后得到了一张图片

然后输入cat.html进入页面,出现了两只猫的图片,并有一段说明:
and its name is uzi. you’ll hear from him later.
替换为uzi.html进入下一题,uzi不是小狗吗 = =!
python challenge 15
http://www.pythonchallenge.com/pc/return/uzi.html

先找到所有有用的提示:
- 图片信息 1**6年1月26日 右下角2月份有29天 说明是闰年 且2月29日为周日
- 页面标题 whom 猜测应该是找人
网页源码
he ain’t the youngest, he is the second # 应该是找到一个年龄列表中第二年轻的
buy flowers for tomorrow # 结合1月26日应该是说明天即1月27日有事件发生结合以上信息
应该是找到1**6年中的所有闰年,且2月29日为周一的时间中第二个年轻的年份,
然后加上1月27日得到一个事件时间,这个时间和一个人有关系。
# run in python 3.0+
def uzi():
from datetime import datetime
def get_week_day(year_, mouth_, day_):
return datetime(year_, mouth_, day_).strftime("%w")
leap_years = [i for i in range(1006, 1997, 10) if (i % 4 == 0 and i % 100 != 0) or i % 400 == 0]
# print (leap_years)
match_year = [y for y in leap_years if get_week_day(y, 2, 29) == "0"]
print (match_year)
print ("%d-01-17" % match_year[-2])
>>> [1176, 1356, 1576, 1756, 1976]
1756-01-17由于python2.7版本中the datetime strftime() methods require year >= 1900,
因此该代码需要运行在python3.0+
最后百度关键词1756年1月27日,著名的音乐大师沃尔弗于格·莫扎特(mozart),诞生于奥地利查尔茨堡。
诞生于,诞生啊。。其实最初我以为送花是第二天有人挂掉了去拜祭。。面壁思过中。。。
python challenge 16
http://www.pythonchallenge.com/pc/return/mozart.html

页面标题提示:let me get this straight
观察图片将粉色的线条对齐排成一列,即将每行像素点循环左移知道粉色点位于最左边。
其中图片模式为索引像素模式,用ps查看得到粉色Idx=195,对应RGB=(255, 0, 255)。
def mozart():
from PIL import Image
org_img = Image.open('img/mozart.gif')
org_size = org_img.size
org_data = list(org_img.getdata())
# new_img = Image.new(org_img.mode, org_size)
new_img = org_img.copy()
new_data = new_img.load()
for y in range(org_size[1]):
line_pixels = org_data[org_size[0] * y: org_size[0] * (y + 1)]
pink_index = line_pixels.index(195)
for x, pixel in enumerate(line_pixels[pink_index:] + line_pixels[:pink_index]):
new_data[x, y] = pixel
new_img.save("img/romance.gif")最后生成答案图片

python challenge 17
http://www.pythonchallenge.com/pc/return/romance.html

做这个题请自觉开启自虐模式,不要问我为什么,我只想静静。
页面标题:eat? 看下源代码图片名字为cookies.jpg
cookies点心?cookie?打开chrome控制台输入alert(document.cookie)
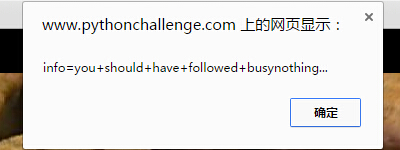
you should have followed busynothing…
结合图片左下角linkedlist页面的图片,想到之前遍历时候找的每个页面,这个应该是遍历找每个页面的cookie信息了。
初步验证,先进入linkedlist的第一个节点:
http://www.pythonchallenge.com/pc/def/linkedlist.php?busynothing=12345
页面内容:
If you came here from level 4 - go back!
You should follow the obvious chain...
and the next busynothing is 44827大概意思是说这个界面如果你是从第四关跳进去的话请返回,显示的关键字会是nothing而非busynothing。
因此一定要从第一个节点进入,不要从linkedlist.php点击图片进入,否则获取不到cookie信息。
弹出的cookie信息为:info=B
第二个节点:http://www.pythonchallenge.com/pc/def/linkedlist.php?busynothing=44827
弹出的cookie信息为:info=Z
是不是有点眼熟,回头找找第8关的BZ2压缩。。
之后是写代码之路,其中cookie模块参考:urllib2模块、cookielib模块
遍历完cookie信息后得到字符串:
BZh91AY%26SY%94%3A%E2I%00%00%21%19%80P%81%11%00%AFg%9E%A0+%00hE%3DM%B5%23%D0%D4%D1%E2%8D%06%A9%FA%26S%D4%D3%21%A1%EAi7h%9B%9A%2B%BF%60%22%C5WX%E1%ADL%80%E8V%3C%C6%A8%DBH%2632%18%A8x%01%08%21%8DS%0B%C8%AF%96KO%CA2%B0%F1%BD%1Du%A0%86%05%92s%B0%92%C4Bc%F1w%24S%85%09%09C%AE%24看看格式应该是转义过的,调用urllib转义函数得到结果:
BZh91AY&SY\x94:\xe2I\x00\x00!\x19\x80P\x81\x11\x00\xafg\x9e\xa0 \x00hE=M\xb5#\xd0\xd4\xd1\xe2\x8d\x06\xa9\xfa&S\xd4\xd3!\xa1\xeai7h\x9b\x9a+\xbf`"\xc5WX\xe1\xadL\x80\xe8V<\xc6\xa8\xdbH&32\x18\xa8x\x01\x08!\x8dS\x0b\xc8\xaf\x96KO\xca2\xb0\xf1\xbd\x1du\xa0\x86\x05\x92s\xb0\x92\xc4Bc\xf1w$S\x85\t\tC\xae$\x90这个看着就很熟悉了,调用bz2进行解压
is it the 26th already? call his father and inform him that "the flowers are on their way". he'll understand.这个结果看的也是格外的忧伤,竟然还有这么多的坑。。看看26th说的是莫扎特,查下莫扎特的老爹为Leopold。
试试Leopold.html,404啊,404!!!
再仔细看,call his father,打电话,电话!!!
调用13关的代码Bert改为Leopold返回555-VIOLIN
参考13关去数字改小写地址为violin.html,竟然还有,呵呵哒。。。
no! i mean yes! but ../stuff/violin.php.再改将上级目录改为/stuff/violin.php
即http://www.pythonchallenge.com/pc/stuff/violin.php
看到图片我以为终于完了,仔细一看,编号呢,没编号肯定还是个坑啊,我内心几乎是崩溃的。。

看下页面提示标题:it’s me. what do you want?
返回页面也没有什么其他信息,答案在哪里?!?!?
想想这个题主题是cookie,回头再看上边的解压出来的提示信息,后半句还没有用到。
inform him that “the flowers are on their way”
翻译是告诉他鲜花已经来路上,暗示要给他携带信息。
也就是说要带上info=“the flowers are on their way"消息去访问这个页面!
cj._cookies.values()[0]['/']['info'].value = 'the+flowers+are+on+their+way'
violin_source = opener.open('http://www.pythonchallenge.com/pc/stuff/violin.php').read()
print violin_source打印出来的页面:
<html>
<head>
<title>it's me. what do you want?</title>
<link rel="stylesheet" type="text/css" href="../style.css">
</head>
<body>
<br><br>
<center><font color="gold">
<img src="leopold.jpg" border="0"/>
<br><br>
oh well, don't you dare to forget the balloons.</font>
</body>
</html>终于出结果了,balloons,感觉已经可以开始google大法了QAQ。。
完整逻辑代码,其中略掉level13的代码:
def romance():
import urllib2
import cookielib
import urllib
cj = cookielib.CookieJar()
handler = urllib2.HTTPCookieProcessor(cj)
opener = urllib2.build_opener(handler)
base_url = "http://www.pythonchallenge.com/pc/def/linkedlist.php"
param = "12345"
times = 1
info = []
while True:
try:
url = "?busynothing=".join([base_url, param])
page_source = opener.open(url).read()
param = re.findall("and the next busynothing is ([0-9]+)", page_source)[0]
ck = cj._cookies.values()[0]['/']['info'].value
info.append(ck)
print "%d -> %s -> %s" % (times, param, ck)
times += 1
# 匹配不到跳到异常
except IndexError:
print "the end is : %d" % times
break
message = "".join(info)
print message
# 转义
message = urllib.unquote_plus(message)
result = message.decode("bz2")
print result
# ---level 13 code ---#
# url = "?busynothing=".join([base_url, param])
# page_source = opener.open(url).read()
cj._cookies.values()[0]['/']['info'].value = 'the+flowers+are+on+their+way'
violin_source = opener.open('http://www.pythonchallenge.com/pc/stuff/violin.php').read()
print violin_sourcepython challenge 18
http://www.pythonchallenge.com/pc/return/balloons.html

页面标题:can you tell the difference?
明显的两张图片亮度不同,英文brightness.
进入该页面后再看源码提示:maybe consider deltas.gz
将该文件下载下来,解压后看到delta.txt里是分为两栏的16进制数据。
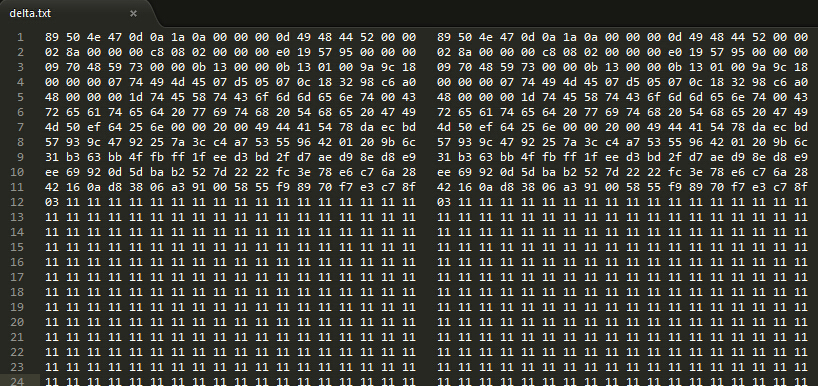
仔细对比两边内容,发现有部分重复的,也就是通过比较两栏内容,来分发字节。
左边特有的,右边特有的,公共部分,分别生成三张图片。
这里需要用到difflib模块来进行数据处理。
def balloons():
import difflib
f_delta = open('files/delta.txt', 'r+')
deltas = f_delta.read().split('\n')
f_delta.close()
left_data = []
right_data = []
for line in deltas:
left_data.append(line[:53]+'\n')
right_data.append(line[56:]+'\n')
diff = difflib.Differ()
cmp_result = list(diff.compare(left_data, right_data))
left_pic = open('img/18-left-diff.png', 'wb')
right_pic = open('img/18-right-diff.png', 'wb')
common_pic = open('img/18-common.png', 'wb')
for line in cmp_result:
bytes = [(chr(int(h, 16))) for h in line[2:].split()]
if line.startswith('-'):
map(left_pic.write, bytes)
elif line.startswith('+'):
map(right_pic.write, bytes)
elif line.startswith(' '):
map(common_pic.write, bytes)
right_pic.close()
left_pic.close()
common_pic.close()最后生成的三张图片

进入http://www.pythonchallenge.com/pc/hex/bin.html
用户名:butter 密码:fly
python challenge 19
http://www.pythonchallenge.com/pc/hex/bin.html
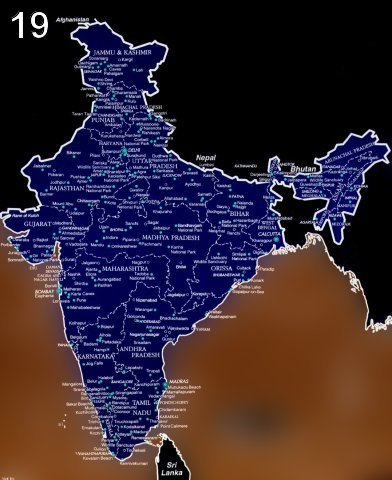
看网页源码,base64加密一段音频数据indian.wav
def hex_bin():
import base64
headers = {
"Authorization": "Basic YnV0dGVyOmZseQ=="
}
page_source = requests.get("http://www.pythonchallenge.com/pc/hex/bin.html", headers=headers).text
wav_data = re.findall(r"base64([\s\S]+?)--", page_source)[0].strip("\n")
indian = open("files/indian.wav", "wb")
indian.write(base64.b64decode(wav_data))
indian.close()打开生成的音频文件,有个怪怪的声音:sorry..
打开sorry界面显示:what are you apologizing for
再回头看看图片,大陆和海洋的颜色是反转的,尝试将音频每一帧反转
def hex_bin():
import base64
import wave
headers = {
"Authorization": "Basic YnV0dGVyOmZseQ=="
}
page_source = requests.get("http://www.pythonchallenge.com/pc/hex/bin.html", headers=headers).text
wav_data = re.findall(r"base64([\s\S]+?)--", page_source)[0].strip("\n")
indian = open("files/indian.wav", "wb")
indian.write(base64.b64decode(wav_data))
indian.close()
indian = wave.open("files/indian.wav", "rb")
reverse = wave.open("files/indian-reverse.wav", "wb")
reverse.setnchannels(1)
reverse.setframerate(indian.getframerate())
reverse.setsampwidth(indian.getsampwidth())
for i in range(indian.getnframes()):
reverse.writeframes(indian.readframes(1)[::-1])
indian.close()
reverse.close()播放下听听,You are a idiot ha ha ha ha ha ha …..
进入idiot.html显示:Now you should apologize,Continue to the next level进入下一关。
python challenge 20
http://www.pythonchallenge.com/pc/hex/idiot2.html

页面标题:go away!
图片下边:but inspecting it carefully is allowed.
大概意思是围栏那边的是私有财产,请离开私有财产,虽然不允许进入,但可以观察。
没有一点思路,谷歌大法好,抓下图片包看下请求头信息:
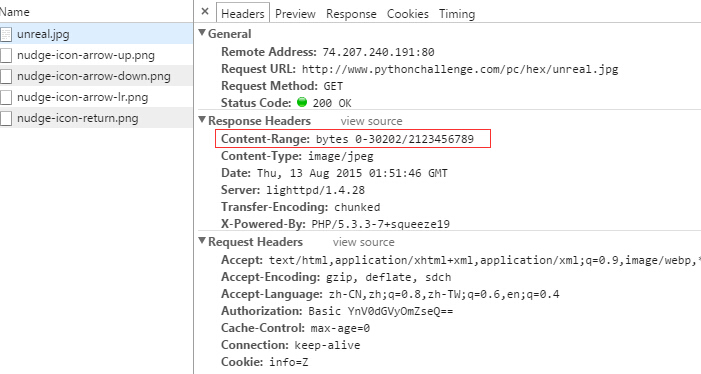
这里的Content-Range的值是: bytes 0-30202/2123456789,这看上去与所谓的“断点续传”十分相似。
从这个信息知道原始图片大小有2123456789个字节,但是目前的“unreal.jpg” 只有前面的30202 个字节,这就说明看到的“unreal.jpg”并不完整。
那就先要把“unreal.jpg”下载完全才行。
要指定请求的字节范围,需要在请求中加入一个叫Range的头,基本形式是“Range: bytes=1000-2345”。
headers = {
"Authorization": "Basic YnV0dGVyOmZseQ==",
"Range": "bytes=30203-"
}
img = requests.get("http://www.pythonchallenge.com/pc/hex/unreal.jpg", headers=headers)
print img.text
>>> u"Why don't you respect my privacy?\n"服务器返回了有意义的信息,因此写个遍历将所有信息打印出来。
def idiot2():
pic_url = "http://www.pythonchallenge.com/pc/hex/unreal.jpg"
next_range = 30203
end_range = 2123456789
while next_range <= end_range:
headers = {
"Authorization": "Basic YnV0dGVyOmZseQ==",
"Range": "bytes=%d-" % next_range
}
img = requests.get(pic_url, headers=headers)
if img.status_code == 206:
print "range : %d -> %s" % (next_range, img.text)
content_range = img.headers.get("Content-Range")
next_range = re.findall(r"bytes.+-(\d+)/", content_range)[0]
next_range = int(next_range) + 1
else:
break
>>>
range : 30203 -> Why don't you respect my privacy?
range : 30237 -> we can go on in this way for really long time.
range : 30284 -> stop this!
range : 30295 -> invader! invader!
range : 30313 -> ok, invader. you are inside now.
Process finished with exit code 0信息中反复提到的入侵者invader,尝试更换下网址为invader.html。
页面显示:Yes! that’s you! 这提示,然并卵。。。
从前边入侵不行,那就从后边入侵试试?
将代码中next_range改为2123456789打印出来为:
esrever ni emankcin wen ruoy si drowssap eht将其反过来
end_text = "esrever ni emankcin wen ruoy si drowssap eht"
result = [text_[::-1] for text_ in end_text.split()[::-1]]
print " ".join(result)
>>> the password is your new nickname in reverse通过读取Content-Range再入侵前一个得到信息:
range : 2123456743 -> and it is hiding at 1152983631.通过这条信息得之其隐藏在1152983631,入侵之后得到pk开头的数据即zip包。
将其下载下来,解压需要密码,密码看前边的提示信息:
the password is your new nickname in reverse
新绰号即为入侵者invader,反过来为redavni。
解压过后生成两个文件,package.pack和readme.txt,打开readme文件内容为:
Yes! This is really level 21 in here.
And yes, After you solve it, you'll be in level 22!
Now for the level:
* We used to play this game when we were kids
* When I had no idea what to do, I looked backwards.已经进入了level 21.
完整代码:
def idiot2():
pic_url = "http://www.pythonchallenge.com/pc/hex/unreal.jpg"
next_range = 30203
end_range = 2123456789
while next_range <= end_range:
headers = {
"Authorization": "Basic YnV0dGVyOmZseQ==",
"Range": "bytes=%d-" % next_range
}
img = requests.get(pic_url, headers=headers)
if img.status_code == 206:
print "range : %d -> %s" % (next_range, img.text)
content_range = img.headers.get("Content-Range")
next_range = re.findall(r"bytes.+-(\d+)/", content_range)[0]
next_range = int(next_range) + 1
else:
break
# reverse
cur_range = 2123456789
end_range = 2123456789
is_download = False
while cur_range <= end_range:
headers = {
"Authorization": "Basic YnV0dGVyOmZseQ==",
"Range": "bytes=%d-" % cur_range
}
img = requests.get(pic_url, headers=headers)
if img.status_code == 206:
if is_download is True:
open("files/invader.zip", "wb").write(img.content)
break
print "range : %d -> %s" % (cur_range, img.text)
content_range = img.headers.get("Content-Range")
cur_range = re.findall(r"bytes (\d+)-", content_range)[0]
cur_range = int(cur_range) - 1
img_text = img.text
result = [text_[::-1] for text_ in img_text.split()[::-1]]
print " ".join(result)
elif img.status_code == 416:
cur_range = img_text.split()[-1].strip(".")
cur_range = int(cur_range)
is_download = True

没有评论:
发表评论